|
|
| version 1.1, 2004/06/16 12:05:30 | version 1.5, 2005/06/10 08:54:06 |
|---|---|
| Line 1 | Line 1 |
| <!-- $Id$ --!> | <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> |
| <html> | <!-- saved from url=(0044)http://euroreves.ined.fr/imach/doc/imach.htm --> |
| <!-- $Id$ --!><HTML><HEAD><TITLE>Computing Health Expectancies using IMaCh</TITLE> | |
| <head> | <META content="text/html; charset=iso-8859-1" http-equiv=Content-Type> |
| <meta http-equiv="Content-Type" | <META content="MSHTML 5.00.3315.2870" name=GENERATOR></HEAD> |
| content="text/html; charset=iso-8859-1"> | <BODY bgColor=#ffffff> |
| <meta name="GENERATOR" content="Microsoft FrontPage Express 2.0"> | <HR color=#ec5e5e SIZE=3> |
| <title>Computing Health Expectancies using IMaCh</title> | |
| <!-- Changed by: Agnes Lievre, 12-Oct-2000 --> | <H1 align=center><FONT color=#00006a>Computing Health Expectancies using |
| <html> | IMaCh</FONT></H1> |
| <H1 align=center><FONT color=#00006a size=5>(a Maximum Likelihood Computer | |
| <head> | Program using Interpolation of Markov Chains)</FONT></H1> |
| <meta http-equiv="Content-Type" | <P align=center> </P> |
| content="text/html; charset=iso-8859-1"> | <P align=center><A href="http://www.ined.fr/"><IMG border=0 height=76 |
| <title>IMaCh</title> | src="Computing Health Expectancies using IMaCh_fichiers/logo-ined.gif" |
| </head> | width=151></A><IMG height=75 |
| src="Computing Health Expectancies using IMaCh_fichiers/euroreves2.gif" | |
| <body bgcolor="#FFFFFF"> | width=151></P> |
| <H3 align=center><A href="http://www.ined.fr/"><FONT | |
| <hr size="3" color="#EC5E5E"> | color=#00006a>INED</FONT></A><FONT color=#00006a> and </FONT><A |
| href="http://euroreves.ined.fr/"><FONT color=#00006a>EUROREVES</FONT></A></H3> | |
| <h1 align="center"><font color="#00006A">Computing Health | <P align=center><FONT color=#00006a size=4><STRONG>Version 0.97, June |
| Expectancies using IMaCh</font></h1> | 2004</STRONG></FONT></P> |
| <HR color=#ec5e5e SIZE=3> | |
| <h1 align="center"><font color="#00006A" size="5">(a Maximum | |
| Likelihood Computer Program using Interpolation of Markov Chains)</font></h1> | <P align=center><FONT color=#00006a><STRONG>Authors of the program: |
| </STRONG></FONT><A href="http://sauvy.ined.fr/brouard"><FONT | |
| <p align="center"> </p> | color=#00006a><STRONG>Nicolas Brouard</STRONG></FONT></A><FONT |
| color=#00006a><STRONG>, senior researcher at the </STRONG></FONT><A | |
| <p align="center"><a href="http://www.ined.fr/"><img | href="http://www.ined.fr/"><FONT color=#00006a><STRONG>Institut National |
| src="logo-ined.gif" border="0" width="151" height="76"></a><img | d'Etudes Démographiques</STRONG></FONT></A><FONT color=#00006a><STRONG> (INED, |
| src="euroreves2.gif" width="151" height="75"></p> | Paris) in the "Mortality, Health and Epidemiology" Research Unit |
| </STRONG></FONT></P> | |
| <h3 align="center"><a href="http://www.ined.fr/"><font | <P align=center><FONT color=#00006a><STRONG>and Agnès Lièvre<BR |
| color="#00006A">INED</font></a><font color="#00006A"> and </font><a | clear=left></STRONG></FONT></P> |
| href="http://euroreves.ined.fr"><font color="#00006A">EUROREVES</font></a></h3> | <H4><FONT color=#00006a>Contribution to the mathematics: C. R. Heathcote |
| </FONT><FONT color=#00006a size=2>(Australian National University, | |
| <p align="center"><font color="#00006A" size="4"><strong>Version | Canberra).</FONT></H4> |
| 0.8a, May 2002</strong></font></p> | <H4><FONT color=#00006a>Contact: Agnès Lièvre (</FONT><A |
| href="mailto:lievre@ined.fr"><FONT | |
| <hr size="3" color="#EC5E5E"> | color=#00006a><I>lievre@ined.fr</I></FONT></A><FONT color=#00006a>) </FONT></H4> |
| <HR> | |
| <p align="center"><font color="#00006A"><strong>Authors of the | |
| program: </strong></font><a href="http://sauvy.ined.fr/brouard"><font | <UL> |
| color="#00006A"><strong>Nicolas Brouard</strong></font></a><font | <LI><A |
| color="#00006A"><strong>, senior researcher at the </strong></font><a | href="http://euroreves.ined.fr/imach/doc/imach.htm#intro">Introduction</A> |
| href="http://www.ined.fr"><font color="#00006A"><strong>Institut | <LI><A href="http://euroreves.ined.fr/imach/doc/imach.htm#data">On what kind |
| National d'Etudes Démographiques</strong></font></a><font | of data can it be used?</A> |
| color="#00006A"><strong> (INED, Paris) in the "Mortality, | <LI><A href="http://euroreves.ined.fr/imach/doc/imach.htm#datafile">The data |
| Health and Epidemiology" Research Unit </strong></font></p> | file</A> |
| <LI><A href="http://euroreves.ined.fr/imach/doc/imach.htm#biaspar">The | |
| <p align="center"><font color="#00006A"><strong>and Agnès | parameter file</A> |
| Lièvre<br clear="left"> | <LI><A href="http://euroreves.ined.fr/imach/doc/imach.htm#running">Running |
| </strong></font></p> | Imach</A> |
| <LI><A href="http://euroreves.ined.fr/imach/doc/imach.htm#output">Output files | |
| <h4><font color="#00006A">Contribution to the mathematics: C. R. | and graphs</A> |
| Heathcote </font><font color="#00006A" size="2">(Australian | <LI><A href="http://euroreves.ined.fr/imach/doc/imach.htm#example">Exemple</A> |
| National University, Canberra).</font></h4> | </LI></UL> |
| <HR> | |
| <h4><font color="#00006A">Contact: Agnès Lièvre (</font><a | |
| href="mailto:lievre@ined.fr"><font color="#00006A"><i>lievre@ined.fr</i></font></a><font | <H2><A name=intro><FONT color=#00006a>Introduction</FONT></A></H2> |
| color="#00006A">) </font></h4> | <P>This program computes <B>Healthy Life Expectancies</B> from |
| <B>cross-longitudinal data</B> using the methodology pioneered by Laditka and | |
| <hr> | Wolf (1). Within the family of Health Expectancies (HE), disability-free life |
| expectancy (DFLE) is probably the most important index to monitor. In low | |
| <ul> | mortality countries, there is a fear that when mortality declines (and therefore total life expectancy improves), the increase will not be as great, leading to an <EM>Expansion of morbidity</EM>. Most of the data collected today, |
| <li><a href="#intro">Introduction</a> </li> | in particular by the international <A href="http://www.reves.org/">REVES</A> |
| <li><a href="#data">On what kind of data can it be used?</a></li> | network on Health Expectancy and the disability process, and most HE indices based on these data, are |
| <li><a href="#datafile">The data file</a> </li> | <EM>cross-sectional</EM>. This means that the information collected comes from a |
| <li><a href="#biaspar">The parameter file</a> </li> | single cross-sectional survey: people from a variety of ages (but often old people) |
| <li><a href="#running">Running Imach</a> </li> | are surveyed on their health status at a single date. The proportion of people |
| <li><a href="#output">Output files and graphs</a> </li> | disabled at each age can then be estimated at that date. This age-specific |
| <li><a href="#example">Exemple</a> </li> | prevalence curve is used to distinguish, within the stationary population |
| </ul> | (which, by definition, is the life table estimated from the vital statistics on |
| mortality at the same date), the disabled population from the disability-free | |
| <hr> | population. Life expectancy (LE) (or total population divided by the yearly |
| number of births or deaths of this stationary population) is then decomposed | |
| <h2><a name="intro"><font color="#00006A">Introduction</font></a></h2> | into disability-free life expectancy (DFLE) and disability life |
| expectancy (DLE). This method of computing HE is usually called the Sullivan | |
| <p>This program computes <b>Healthy Life Expectancies</b> from <b>cross-longitudinal | method (after the author who first described it).</P> |
| data</b> using the methodology pioneered by Laditka and Wolf (1). | <P>The age-specific proportions of people disabled (prevalence of disability) are |
| Within the family of Health Expectancies (HE), Disability-free | dependent upon the historical flows from entering disability and recovering in the past. The age-specific forces (or incidence rates) of entering |
| life expectancy (DFLE) is probably the most important index to | disability or recovering a good health, estimated over a recent period of time (as period forces of mortality), are reflecting current conditions and |
| monitor. In low mortality countries, there is a fear that when | therefore can be used at each age to forecast the future of this cohort <EM>if |
| mortality declines, the increase in DFLE is not proportionate to | nothing changes in the future</EM>, i.e to forecast the prevalence of disability of each cohort. Our finding (2) is that the period prevalence of disability |
| the increase in total Life expectancy. This case is called the <em>Expansion | (computed from period incidences) is lower than the cross-sectional prevalence. |
| of morbidity</em>. Most of the data collected today, in | For example if a country is improving its technology of prosthesis, the |
| particular by the international <a href="http://www.reves.org">REVES</a> | incidence of recovering the ability to walk will be higher at each (old) age, |
| network on Health expectancy, and most HE indices based on these | but the prevalence of disability will only slightly reflect an improvement because |
| data, are <em>cross-sectional</em>. It means that the information | the prevalence is mostly affected by the history of the cohort and not by recent |
| collected comes from a single cross-sectional survey: people from | period effects. To measure the period improvement we have to simulate the future |
| various ages (but mostly old people) are surveyed on their health | of a cohort of new-borns entering or leaving the disability state or |
| status at a single date. Proportion of people disabled at each | dying at each age according to the incidence rates measured today on different cohorts. The |
| age, can then be measured at that date. This age-specific | proportion of people disabled at each age in this simulated cohort will be much |
| prevalence curve is then used to distinguish, within the | lower that the proportions observed at each age in a cross-sectional survey. |
| stationary population (which, by definition, is the life table | This new prevalence curve introduced in a life table will give a more realistic |
| estimated from the vital statistics on mortality at the same | HE level than the Sullivan method which mostly reflects the history of health |
| date), the disable population from the disability-free | conditions in a country.</P> |
| population. Life expectancy (LE) (or total population divided by | <P>Therefore, the main question is how can we measure incidence rates from |
| the yearly number of births or deaths of this stationary | cross-longitudinal surveys? This is the goal of the IMaCH program. From your |
| population) is then decomposed into DFLE and DLE. This method of | data and using IMaCH you can estimate period HE as well as the Sullivan HE. In addition the standard errors of the HE are computed.</P> |
| computing HE is usually called the Sullivan method (from the name | <P>A cross-longitudinal survey consists of a first survey ("cross") where |
| of the author who first described it).</p> | individuals of different ages are interviewed about their health status or degree |
| of disability. At least a second wave of interviews ("longitudinal") should | |
| <p>Age-specific proportions of people disable are very difficult | measure each individual new health status. Health expectancies are computed from |
| to forecast because each proportion corresponds to historical | the transitions observed between waves (interviews) and are computed for each degree of |
| conditions of the cohort and it is the result of the historical | severity of disability (number of health states). The more degrees of severity considered, the more |
| flows from entering disability and recovering in the past until | time is necessary to reach the Maximum Likelihood of the parameters involved in |
| today. The age-specific intensities (or incidence rates) of | the model. Considering only two states of disability (disabled and healthy) is |
| entering disability or recovering a good health, are reflecting | generally enough but the computer program works also with more health |
| actual conditions and therefore can be used at each age to | states.<BR><BR>The simplest model for the transition probabilities is the multinomial logistic model where |
| forecast the future of this cohort. For example if a country is | <I>pij</I> is the probability to be observed in state <I>j</I> at the second |
| improving its technology of prosthesis, the incidence of | wave conditional to be observed in state <EM>i</EM> at the first wave. Therefore |
| recovering the ability to walk will be higher at each (old) age, | a simple model is: log<EM>(pij/pii)= aij + bij*age+ cij*sex,</EM> where |
| but the prevalence of disability will only slightly reflect an | '<I>age</I>' is age and '<I>sex</I>' is a covariate. The advantage that this |
| improve because the prevalence is mostly affected by the history | computer program claims, is that if the delay between waves is not |
| of the cohort and not by recent period effects. To measure the | identical for each individual, or if some individual missed an interview, the |
| period improvement we have to simulate the future of a cohort of | information is not rounded or lost, but taken into account using an |
| new-borns entering or leaving at each age the disability state or | interpolation or extrapolation. <I>hPijx</I> is the probability to be observed |
| dying according to the incidence rates measured today on | in state <I>i</I> at age <I>x+h</I> conditional on the observed state <I>i</I> |
| different cohorts. The proportion of people disabled at each age | at age <I>x</I>. The delay '<I>h</I>' can be split into an exact number |
| in this simulated cohort will be much lower (using the exemple of | (<I>nh*stepm</I>) of unobserved intermediate states. This elementary transition |
| an improvement) that the proportions observed at each age in a | (by month or quarter, trimester, semester or year) is modeled as the above multinomial |
| cross-sectional survey. This new prevalence curve introduced in a | logistic. The <I>hPx</I> matrix is simply the matrix product of <I>nh*stepm</I> |
| life table will give a much more actual and realistic HE level | elementary matrices and the contribution of each individual to the likelihood is |
| than the Sullivan method which mostly measured the History of | simply <I>hPijx</I>. <BR></P> |
| health conditions in this country.</p> | <P>The program presented in this manual is a general program named |
| <STRONG>IMaCh</STRONG> (for <STRONG>I</STRONG>nterpolated | |
| <p>Therefore, the main question is how to measure incidence rates | <STRONG>MA</STRONG>rkov <STRONG>CH</STRONG>ain), designed to analyse transitions from longitudinal surveys. The first step is the estimation of the set of the parameters of a model for the |
| from cross-longitudinal surveys? This is the goal of the IMaCH | transition probabilities between an initial state and a final state. |
| program. From your data and using IMaCH you can estimate period | From there, the computer program produces indicators such as the observed and |
| HE and not only Sullivan's HE. Also the standard errors of the HE | stationary prevalence, life expectancies and their variances both numerically and graphically. Our |
| are computed.</p> | transition model consists of absorbing and non-absorbing states assuming the |
| possibility of return across the non-absorbing states. The main advantage of | |
| <p>A cross-longitudinal survey consists in a first survey | this package, compared to other programs for the analysis of transition data |
| ("cross") where individuals from different ages are | (for example: Proc Catmod of SAS<SUP>®</SUP>) is that the whole individual |
| interviewed on their health status or degree of disability. At | information is used even if an interview is missing, a state or a date is |
| least a second wave of interviews ("longitudinal") | unknown or when the delay between waves is not identical for each individual. |
| should measure each new individual health status. Health | The program is dependent upon a set of parameters inputted by the user: selection of a sub-sample, |
| expectancies are computed from the transitions observed between | number of absorbing and non-absorbing states, number of waves to be taken in account , a tolerance level for the |
| waves and are computed for each degree of severity of disability | maximization function, the periodicity of the transitions (we can compute |
| (number of life states). More degrees you consider, more time is | annual, quarterly or monthly transitions), covariates in the model. IMaCh works on |
| necessary to reach the Maximum Likelihood of the parameters | Windows or on Unix platform.<BR></P> |
| involved in the model. Considering only two states of disability | <HR> |
| (disable and healthy) is generally enough but the computer | |
| program works also with more health statuses.<br> | <P>(1) Laditka S. B. and Wolf, D. (1998), New Methods for Analyzing |
| <br> | Active Life Expectancy. <I>Journal of Aging and Health</I>. Vol 10, No. 2. </P> |
| The simplest model is the multinomial logistic model where <i>pij</i> | <P>(2) <A |
| is the probability to be observed in state <i>j</i> at the second | href="http://taylorandfrancis.metapress.com/app/home/contribution.asp?wasp=1f99bwtvmk5yrb7hlhw3&referrer=parent&backto=issue,1,2;journal,2,5;linkingpublicationresults,1:300265,1">Lièvre |
| wave conditional to be observed in state <em>i</em> at the first | A., Brouard N. and Heathcote Ch. (2003) Estimating Health Expectancies from |
| wave. Therefore a simple model is: log<em>(pij/pii)= aij + | Cross-longitudinal surveys. <EM>Mathematical Population Studies</EM>.- 10(4), |
| bij*age+ cij*sex,</em> where '<i>age</i>' is age and '<i>sex</i>' | pp. 211-248</A> |
| is a covariate. The advantage that this computer program claims, | <HR> |
| comes from that if the delay between waves is not identical for | |
| each individual, or if some individual missed an interview, the | <H2><A name=data><FONT color=#00006a>What kind of data is required?</FONT></A></H2> |
| information is not rounded or lost, but taken into account using | <P>The minimum data required for a transition model is the recording of a set of |
| an interpolation or extrapolation. <i>hPijx</i> is the | individuals interviewed at a first date and interviewed once more. From the observations of an individual, we obtain a follow-up over |
| probability to be observed in state <i>i</i> at age <i>x+h</i> | time of the occurrence of a specific event. In this documentation, the event is |
| conditional to the observed state <i>i</i> at age <i>x</i>. The | related to health state, but the program can be applied to many |
| delay '<i>h</i>' can be split into an exact number (<i>nh*stepm</i>) | longitudinal studies with different contexts. To build the data file |
| of unobserved intermediate states. This elementary transition (by | as explained |
| month or quarter trimester, semester or year) is modeled as a | in the next section, you must have the month and year of each interview and |
| multinomial logistic. The <i>hPx</i> matrix is simply the matrix | the corresponding health state. In order to get age, date of birth (month |
| product of <i>nh*stepm</i> elementary matrices and the | and year) are required (missing values are allowed for month). Date of death |
| contribution of each individual to the likelihood is simply <i>hPijx</i>. | (month and year) is an important information also required if the individual is |
| <br> | dead. Shorter steps (i.e. a month) will more closely take into account the |
| </p> | survival time after the last interview.</P> |
| <HR> | |
| <p>The program presented in this manual is a quite general | |
| program named <strong>IMaCh</strong> (for <strong>I</strong>nterpolated | <H2><A name=datafile><FONT color=#00006a>The data file</FONT></A></H2> |
| <strong>MA</strong>rkov <strong>CH</strong>ain), designed to | <P>In this example, 8,000 people have been interviewed in a cross-longitudinal |
| analyse transition data from longitudinal surveys. The first step | survey of 4 waves (1984, 1986, 1988, 1990). Some people missed 1, 2 or 3 |
| is the parameters estimation of a transition probabilities model | interviews. Health states are healthy (1) and disabled (2). The survey is not a |
| between an initial status and a final status. From there, the | real one but a simulation of the American Longitudinal Survey on Aging. The |
| computer program produces some indicators such as observed and | disability state is defined as dependence in at least one of four ADLs (Activities |
| stationary prevalence, life expectancies and their variances and | of daily living, like bathing, eating, walking). Therefore, even if the |
| graphs. Our transition model consists in absorbing and | individuals interviewed in the sample are virtual, the information in |
| non-absorbing states with the possibility of return across the | this sample is close to reality for the United States. Sex is not recorded |
| non-absorbing states. The main advantage of this package, | is this sample. The LSOA survey is biased in the sense that people |
| compared to other programs for the analysis of transition data | living in an institution were not included in the first interview in |
| (For example: Proc Catmod of SAS<sup>®</sup>) is that the whole | 1984. Thus the prevalence of disability observed in 1984 is lower than |
| individual information is used even if an interview is missing, a | the true prevalence at old ages. However when people moved into an |
| status or a date is unknown or when the delay between waves is | institution, they were interviewed there in 1986, 1988 and 1990. Thus |
| not identical for each individual. The program can be executed | the incidences of disabilities are not biased. Cross-sectional |
| according to parameters: selection of a sub-sample, number of | prevalences of disability at old ages are thus artificially increasing in 1986, |
| absorbing and non-absorbing states, number of waves taken in | 1988 and 1990 because of a greater proportion of the sample |
| account (the user inputs the first and the last interview), a | institutionalized. Our article (Lièvre A., Brouard N. and Heathcote |
| tolerance level for the maximization function, the periodicity of | Ch. (2003)) shows the opposite: the period prevalence based on the |
| the transitions (we can compute annual, quarterly or monthly | incidences is lower at old |
| transitions), covariates in the model. It works on Windows or on | ages than the adjusted cross-sectional prevalence illustrating that |
| Unix.<br> | there has been significant progress against disability.</P> |
| </p> | <P>Each line of the data set (named <A |
| href="http://euroreves.ined.fr/imach/doc/data1.txt">data1.txt</A> in this first | |
| <hr> | example) is an individual record. Fields are separated by blanks: </P> |
| <UL> | |
| <p>(1) Laditka, Sarah B. and Wolf, Douglas A. (1998), "New | <LI><B>Index number</B>: positive number (field 1) |
| Methods for Analyzing Active Life Expectancy". <i>Journal of | <LI><B>First covariate</B> positive number (field 2) |
| Aging and Health</i>. Vol 10, No. 2. </p> | <LI><B>Second covariate</B> positive number (field 3) |
| <LI><A name=Weight><B>Weight</B></A>: positive number (field 4) . In most | |
| <hr> | surveys individuals are weighted to account for stratification of the |
| sample. | |
| <h2><a name="data"><font color="#00006A">On what kind of data can | <LI><B>Date of birth</B>: coded as mm/yyyy. Missing dates are coded as 99/9999 |
| it be used?</font></a></h2> | (field 5) |
| <LI><B>Date of death</B>: coded as mm/yyyy. Missing dates are coded as 99/9999 | |
| <p>The minimum data required for a transition model is the | (field 6) |
| recording of a set of individuals interviewed at a first date and | <LI><B>Date of first interview</B>: coded as mm/yyyy. Missing dates are coded |
| interviewed again at least one another time. From the | as 99/9999 (field 7) |
| observations of an individual, we obtain a follow-up over time of | <LI><B>Status at first interview</B>: positive number. Missing values ar coded |
| the occurrence of a specific event. In this documentation, the | -1. (field 8) |
| event is related to health status at older ages, but the program | <LI><B>Date of second interview</B>: coded as mm/yyyy. Missing dates are coded |
| can be applied on a lot of longitudinal studies in different | as 99/9999 (field 9) |
| contexts. To build the data file explained into the next section, | <LI><STRONG>Status at second interview</STRONG> positive number. Missing |
| you must have the month and year of each interview and the | values ar coded -1. (field 10) |
| corresponding health status. But in order to get age, date of | <LI><B>Date of third interview</B>: coded as mm/yyyy. Missing dates are coded |
| birth (month and year) is required (missing values is allowed for | as 99/9999 (field 11) |
| month). Date of death (month and year) is an important | <LI><STRONG>Status at third interview</STRONG> positive number. Missing values |
| information also required if the individual is dead. Shorter | ar coded -1. (field 12) |
| steps (i.e. a month) will more closely take into account the | <LI><B>Date of fourth interview</B>: coded as mm/yyyy. Missing dates are coded |
| survival time after the last interview.</p> | as 99/9999 (field 13) |
| <LI><STRONG>Status at fourth interview</STRONG> positive number. Missing | |
| <hr> | values are coded -1. (field 14) |
| <LI>etc </LI></UL> | |
| <h2><a name="datafile"><font color="#00006A">The data file</font></a></h2> | <P> </P> |
| <P>If you do not wish to include information on weights or | |
| <p>In this example, 8,000 people have been interviewed in a | covariates, you must fill the column with a number (e.g. 1) since all |
| cross-longitudinal survey of 4 waves (1984, 1986, 1988, 1990). | fields must be present.</P> |
| Some people missed 1, 2 or 3 interviews. Health statuses are | <HR> |
| healthy (1) and disable (2). The survey is not a real one. It is | |
| a simulation of the American Longitudinal Survey on Aging. The | <H2><FONT color=#00006a>Your first example parameter file</FONT><A |
| disability state is defined if the individual missed one of four | href="http://euroreves.ined.fr/imach"></A><A name=uio></A></H2> |
| ADL (Activity of daily living, like bathing, eating, walking). | <H2><A name=biaspar></A>#Imach version 0.97b, June 2004, INED-EUROREVES </H2> |
| Therefore, even is the individuals interviewed in the sample are | <P>This first line was a comment. Comments line start with a '#'.</P> |
| virtual, the information brought with this sample is close to the | <H4><FONT color=#ff0000>First uncommented line</FONT></H4><PRE>title=1st_example datafile=data1.txt lastobs=8600 firstpass=1 lastpass=4</PRE> |
| situation of the United States. Sex is not recorded is this | <UL> |
| sample.</p> | <LI><B>title=</B> 1st_example is title of the run. |
| <LI><B>datafile=</B> data1.txt is the name of the data set. Our example is a | |
| <p>Each line of the data set (named <a href="data1.txt">data1.txt</a> | six years follow-up survey. It consists of a baseline followed by 3 |
| in this first example) is an individual record which fields are: </p> | reinterviews. |
| <LI><B>lastobs=</B> 8600 the program is able to run on a subsample where the | |
| <ul> | last observation number is lastobs. It can be set a bigger number than the |
| <li><b>Index number</b>: positive number (field 1) </li> | real number of observations (e.g. 100000). In this example, maximisation will |
| <li><b>First covariate</b> positive number (field 2) </li> | be done on the first 8600 records. |
| <li><b>Second covariate</b> positive number (field 3) </li> | <LI><B>firstpass=1</B> , <B>lastpass=4 </B>If there are more than two interviews |
| <li><a name="Weight"><b>Weight</b></a>: positive number | in the survey, the program can be run on selected transitions periods. |
| (field 4) . In most surveys individuals are weighted | firstpass=1 means the first interview included in the calculation is the |
| according to the stratification of the sample.</li> | baseline survey. lastpass=4 means that the last interview to be |
| <li><b>Date of birth</b>: coded as mm/yyyy. Missing dates are | included will be by the 4th. </LI></UL> |
| coded as 99/9999 (field 5) </li> | <P> </P> |
| <li><b>Date of death</b>: coded as mm/yyyy. Missing dates are | <H4><A name=biaspar-2><FONT color=#ff0000>Second uncommented |
| coded as 99/9999 (field 6) </li> | line</FONT></A></H4><PRE>ftol=1.e-08 stepm=1 ncovcol=2 nlstate=2 ndeath=1 maxwav=4 mle=1 weight=0</PRE> |
| <li><b>Date of first interview</b>: coded as mm/yyyy. Missing | <UL> |
| dates are coded as 99/9999 (field 7) </li> | <LI><B>ftol=1e-8</B> Convergence tolerance on the function value in the |
| <li><b>Status at first interview</b>: positive number. | maximisation of the likelihood. Choosing a correct value for ftol is |
| Missing values ar coded -1. (field 8) </li> | difficult. 1e-8 is the correct value for a 32 bit computer. |
| <li><b>Date of second interview</b>: coded as mm/yyyy. | <LI><B>stepm=1</B> The time unit in months for interpolation. Examples: |
| Missing dates are coded as 99/9999 (field 9) </li> | <UL> |
| <li><strong>Status at second interview</strong> positive | <LI>If stepm=1, the unit is a month |
| number. Missing values ar coded -1. (field 10) </li> | <LI>If stepm=4, the unit is a trimester |
| <li><b>Date of third interview</b>: coded as mm/yyyy. Missing | <LI>If stepm=12, the unit is a year |
| dates are coded as 99/9999 (field 11) </li> | <LI>If stepm=24, the unit is two years |
| <li><strong>Status at third interview</strong> positive | <LI>... </LI></UL> |
| number. Missing values ar coded -1. (field 12) </li> | <LI><B>ncovcol=2</B> Number of covariate columns included in the datafile |
| <li><b>Date of fourth interview</b>: coded as mm/yyyy. | before the column for the date of birth. You can include covariates |
| Missing dates are coded as 99/9999 (field 13) </li> | that will not be used in the model as this number is not the number of covariates that will |
| <li><strong>Status at fourth interview</strong> positive | be specified by the model. The 'model' syntax describes the covariates to be |
| number. Missing values are coded -1. (field 14) </li> | taken into account during the run. |
| <li>etc</li> | <LI><B>nlstate=2</B> Number of non-absorbing (alive) states. Here we have two |
| </ul> | alive states: disability-free is coded 1 and disability is coded 2. |
| <LI><B>ndeath=1</B> Number of absorbing states. The absorbing state death is | |
| <p> </p> | coded 3. |
| <LI><B>maxwav=4</B> Number of waves in the datafile. | |
| <p>If your longitudinal survey do not include information about | <LI><A name=mle><B>mle</B></A><B>=1</B> Option for the Maximisation Likelihood |
| weights or covariates, you must fill the column with a number | Estimation. |
| (e.g. 1) because a missing field is not allowed.</p> | <UL> |
| <LI>If mle=1 the program does the maximisation and the calculation of health | |
| <hr> | expectancies |
| <LI>If mle=0 the program only does the calculation of the health | |
| <h2><font color="#00006A">Your first example parameter file</font><a | expectancies and other indices and graphs but without the maximization. |
| href="http://euroreves.ined.fr/imach"></a><a name="uio"></a></h2> | There are also other possible values: |
| <UL> | |
| <h2><a name="biaspar"></a>#Imach version 0.8a, May 2002, | <LI>If mle=-1 you get a template for the number of parameters |
| INED-EUROREVES </h2> | and the size of the variance-covariance matrix. This is useful if the model is |
| complex with many covariates. | |
| <p>This is a comment. Comments start with a '#'.</p> | <LI>If mle=-3 IMaCh computes the mortality but without any health status |
| (May 2004) | |
| <h4><font color="#FF0000">First uncommented line</font></h4> | <LI>If mle=2 IMach likelihood corresponds to a linear interpolation |
| <LI>If mle=3 IMach likelihood corresponds to an exponential | |
| <pre>title=1st_example datafile=data1.txt lastobs=8600 firstpass=1 lastpass=4</pre> | inter-extrapolation |
| <LI>If mle=4 IMach likelihood corresponds to no inter-extrapolation, thus biasing the results. | |
| <ul> | <LI>If mle=5 IMach likelihood corresponds to no inter-extrapolation, and |
| <li><b>title=</b> 1st_example is title of the run. </li> | before the correction of the Jackson's bug (avoid this). </LI></UL></LI></UL> |
| <li><b>datafile=</b> data1.txt is the name of the data set. | <LI><B>weight=0</B> Provides the possibility of adding weights. |
| Our example is a six years follow-up survey. It consists | <UL> |
| in a baseline followed by 3 reinterviews. </li> | <LI>If weight=0 no weights are included |
| <li><b>lastobs=</b> 8600 the program is able to run on a | <LI>If weight=1 the maximisation integrates the weights which are in field |
| subsample where the last observation number is lastobs. | <A href="http://euroreves.ined.fr/imach/doc/imach.htm#Weight">4</A> |
| It can be set a bigger number than the real number of | </LI></UL></LI></UL> |
| observations (e.g. 100000). In this example, maximisation | <H4><FONT color=#ff0000>Covariates</FONT></H4> |
| will be done on the 8600 first records. </li> | <P>Intercept and age are automatically included in the model. Additional |
| <li><b>firstpass=1</b> , <b>lastpass=4 </b>In case of more | covariates can be included with the command: </P><PRE>model=<EM>list of covariates</EM></PRE> |
| than two interviews in the survey, the program can be run | <UL> |
| on selected transitions periods. firstpass=1 means the | <LI>if<STRONG> model=. </STRONG>then no covariates are included |
| first interview included in the calculation is the | <LI>if <STRONG>model=V1</STRONG> the model includes the first covariate (field |
| baseline survey. lastpass=4 means that the information | 2) |
| brought by the 4th interview is taken into account.</li> | <LI>if <STRONG>model=V2 </STRONG>the model includes the second covariate |
| </ul> | (field 3) |
| <LI>if <STRONG>model=V1+V2 </STRONG>the model includes the first and the | |
| <p> </p> | second covariate (fields 2 and 3) |
| <LI>if <STRONG>model=V1*V2 </STRONG>the model includes the product of the | |
| <h4><a name="biaspar-2"><font color="#FF0000">Second uncommented | first and the second covariate (fields 2 and 3) |
| line</font></a></h4> | <LI>if <STRONG>model=V1+V1*age</STRONG> the model includes the product |
| covariate*age </LI></UL> | |
| <pre>ftol=1.e-08 stepm=1 ncovcol=2 nlstate=2 ndeath=1 maxwav=4 mle=1 weight=0</pre> | <P>In this example, we have two covariates in the data file (fields 2 and 3). |
| The number of covariates included in the data file between the id and the date | |
| <ul> | of birth is ncovcol=2 (it was named ncov in version prior to 0.8). If you have 3 |
| <li><b>ftol=1e-8</b> Convergence tolerance on the function | covariates in the datafile (fields 2, 3 and 4), you will set ncovcol=3. Then you |
| value in the maximisation of the likelihood. Choosing a | can run the programme with a new parametrisation taking into account the third |
| correct value for ftol is difficult. 1e-8 is a correct | covariate. For example, <STRONG>model=V1+V3 </STRONG>estimates a model with the |
| value for a 32 bits computer.</li> | first and third covariates. More complicated models can be used, but this will |
| <li><b>stepm=1</b> Time unit in months for interpolation. | take more time to converge. With a simple model (no covariates), the programme |
| Examples:<ul> | estimates 8 parameters. Adding covariates increases the number of parameters : |
| <li>If stepm=1, the unit is a month </li> | 12 for <STRONG>model=V1, </STRONG>16 for <STRONG>model=V1+V1*age </STRONG>and 20 |
| <li>If stepm=4, the unit is a trimester</li> | for <STRONG>model=V1+V2+V3.</STRONG></P> |
| <li>If stepm=12, the unit is a year </li> | <H4><FONT color=#ff0000>Guess values for optimization</FONT><FONT color=#00006a> |
| <li>If stepm=24, the unit is two years</li> | </FONT></H4> |
| <li>... </li> | <P>You must write the initial guess values of the parameters for optimization. |
| </ul> | The number of parameters, <EM>N</EM> depends on the number of absorbing states |
| </li> | and non-absorbing states and on the number of covariates in the model (ncovmodel). <BR><EM>N</EM> is |
| <li><b>ncovcol=2</b> Number of covariate columns in the | given by the formula <EM>N</EM>=(<EM>nlstate</EM> + |
| datafile which precede the date of birth. Here you can | <EM>ndeath</EM>-1)*<EM>nlstate</EM>*<EM>ncovmodel</EM> . <BR><BR>Thus in |
| put variables that won't necessary be used during the | the simple case with 2 covariates in the model(the model is log (pij/pii) = aij + bij * age |
| run. It is not the number of covariates that will be | where intercept and age are the two covariates), and 2 health states (1 for |
| specified by the model. The 'model' syntax describe the | disability-free and 2 for disability) and 1 absorbing state (3), you must enter |
| covariates to take into account. </li> | 8 initials values, a12, b12, a13, b13, a21, b21, a23, b23. You can start with |
| <li><b>nlstate=2</b> Number of non-absorbing (alive) states. | zeros as in this example, but if you have a more precise set (for example from |
| Here we have two alive states: disability-free is coded 1 | an earlier run) you can enter it and it will speed up the convergence<BR>Each of the four |
| and disability is coded 2. </li> | lines starts with indices "ij": <B>ij aij bij</B> </P> |
| <li><b>ndeath=1</b> Number of absorbing states. The absorbing | <BLOCKQUOTE><PRE># Guess values of aij and bij in log (pij/pii) = aij + bij * age |
| state death is coded 3. </li> | |
| <li><b>maxwav=4</b> Number of waves in the datafile.</li> | |
| <li><a name="mle"><b>mle</b></a><b>=1</b> Option for the | |
| Maximisation Likelihood Estimation. <ul> | |
| <li>If mle=1 the program does the maximisation and | |
| the calculation of health expectancies </li> | |
| <li>If mle=0 the program only does the calculation of | |
| the health expectancies. </li> | |
| </ul> | |
| </li> | |
| <li><b>weight=0</b> Possibility to add weights. <ul> | |
| <li>If weight=0 no weights are included </li> | |
| <li>If weight=1 the maximisation integrates the | |
| weights which are in field <a href="#Weight">4</a></li> | |
| </ul> | |
| </li> | |
| </ul> | |
| <h4><font color="#FF0000">Covariates</font></h4> | |
| <p>Intercept and age are systematically included in the model. | |
| Additional covariates can be included with the command: </p> | |
| <pre>model=<em>list of covariates</em></pre> | |
| <ul> | |
| <li>if<strong> model=. </strong>then no covariates are | |
| included</li> | |
| <li>if <strong>model=V1</strong> the model includes the first | |
| covariate (field 2)</li> | |
| <li>if <strong>model=V2 </strong>the model includes the | |
| second covariate (field 3)</li> | |
| <li>if <strong>model=V1+V2 </strong>the model includes the | |
| first and the second covariate (fields 2 and 3)</li> | |
| <li>if <strong>model=V1*V2 </strong>the model includes the | |
| product of the first and the second covariate (fields 2 | |
| and 3)</li> | |
| <li>if <strong>model=V1+V1*age</strong> the model includes | |
| the product covariate*age</li> | |
| </ul> | |
| <p>In this example, we have two covariates in the data file | |
| (fields 2 and 3). The number of covariates included in the data | |
| file between the id and the date of birth is ncovcol=2 (it was | |
| named ncov in version prior to 0.8). If you have 3 covariates in | |
| the datafile (fields 2, 3 and 4), you will set ncovcol=3. Then | |
| you can run the programme with a new parametrisation taking into | |
| account the third covariate. For example, <strong>model=V1+V3 </strong>estimates | |
| a model with the first and third covariates. More complicated | |
| models can be used, but it will takes more time to converge. With | |
| a simple model (no covariates), the programme estimates 8 | |
| parameters. Adding covariates increases the number of parameters | |
| : 12 for <strong>model=V1, </strong>16 for <strong>model=V1+V1*age | |
| </strong>and 20 for <strong>model=V1+V2+V3.</strong></p> | |
| <h4><font color="#FF0000">Guess values for optimization</font><font | |
| color="#00006A"> </font></h4> | |
| <p>You must write the initial guess values of the parameters for | |
| optimization. The number of parameters, <em>N</em> depends on the | |
| number of absorbing states and non-absorbing states and on the | |
| number of covariates. <br> | |
| <em>N</em> is given by the formula <em>N</em>=(<em>nlstate</em> + | |
| <em>ndeath</em>-1)*<em>nlstate</em>*<em>ncovmodel</em> . <br> | |
| <br> | |
| Thus in the simple case with 2 covariates (the model is log | |
| (pij/pii) = aij + bij * age where intercept and age are the two | |
| covariates), and 2 health degrees (1 for disability-free and 2 | |
| for disability) and 1 absorbing state (3), you must enter 8 | |
| initials values, a12, b12, a13, b13, a21, b21, a23, b23. You can | |
| start with zeros as in this example, but if you have a more | |
| precise set (for example from an earlier run) you can enter it | |
| and it will speed up them<br> | |
| Each of the four lines starts with indices "ij": <b>ij | |
| aij bij</b> </p> | |
| <blockquote> | |
| <pre># Guess values of aij and bij in log (pij/pii) = aij + bij * age | |
| 12 -14.155633 0.110794 | 12 -14.155633 0.110794 |
| 13 -7.925360 0.032091 | 13 -7.925360 0.032091 |
| 21 -1.890135 -0.029473 | 21 -1.890135 -0.029473 |
| 23 -6.234642 0.022315 </pre> | 23 -6.234642 0.022315 </PRE></BLOCKQUOTE> |
| </blockquote> | <P>or, to simplify (in most of cases it converges but there is no warranty!): |
| </P> | |
| <p>or, to simplify (in most of cases it converges but there is no | <BLOCKQUOTE><PRE>12 0.0 0.0 |
| warranty!): </p> | |
| <blockquote> | |
| <pre>12 0.0 0.0 | |
| 13 0.0 0.0 | 13 0.0 0.0 |
| 21 0.0 0.0 | 21 0.0 0.0 |
| 23 0.0 0.0</pre> | 23 0.0 0.0</PRE></BLOCKQUOTE> |
| </blockquote> | <P>In order to speed up the convergence you can make a first run with a large |
| stepm i.e stepm=12 or 24 and then decrease the stepm until stepm=1 month. If | |
| <p>In order to speed up the convergence you can make a first run | newstepm is the new shorter stepm and stepm can be expressed as a multiple of |
| with a large stepm i.e stepm=12 or 24 and then decrease the stepm | newstepm, like newstepm=n stepm, then the following approximation holds: </P><PRE>aij(stepm) = aij(n . stepm) - ln(n) |
| until stepm=1 month. If newstepm is the new shorter stepm and | </PRE> |
| stepm can be expressed as a multiple of newstepm, like newstepm=n | <P>and </P><PRE>bij(stepm) = bij(n . stepm) .</PRE> |
| stepm, then the following approximation holds: </p> | <P>For example if you already ran with stepm=6 (a 6 months interval) and got:<BR></P><PRE># Parameters |
| <pre>aij(stepm) = aij(n . stepm) - ln(n) | |
| </pre> | |
| <p>and </p> | |
| <pre>bij(stepm) = bij(n . stepm) .</pre> | |
| <p>For example if you already ran for a 6 months interval and | |
| got:<br> | |
| </p> | |
| <pre># Parameters | |
| 12 -13.390179 0.126133 | 12 -13.390179 0.126133 |
| 13 -7.493460 0.048069 | 13 -7.493460 0.048069 |
| 21 0.575975 -0.041322 | 21 0.575975 -0.041322 |
| 23 -4.748678 0.030626 | 23 -4.748678 0.030626 |
| </pre> | </PRE> |
| <P>Then you now want to get the monthly estimates, you can guess the aij by | |
| <p>If you now want to get the monthly estimates, you can guess | subtracting ln(6)= 1.7917<BR>and running using<BR></P><PRE>12 -15.18193847 0.126133 |
| the aij by substracting ln(6)= 1,7917<br> | |
| and running<br> | |
| </p> | |
| <pre>12 -15.18193847 0.126133 | |
| 13 -9.285219469 0.048069 | 13 -9.285219469 0.048069 |
| 21 -1.215784469 -0.041322 | 21 -1.215784469 -0.041322 |
| 23 -6.540437469 0.030626 | 23 -6.540437469 0.030626 |
| </pre> | </PRE> |
| <P>and get<BR></P><PRE>12 -15.029768 0.124347 | |
| <p>and get<br> | |
| </p> | |
| <pre>12 -15.029768 0.124347 | |
| 13 -8.472981 0.036599 | 13 -8.472981 0.036599 |
| 21 -1.472527 -0.038394 | 21 -1.472527 -0.038394 |
| 23 -6.553602 0.029856 | 23 -6.553602 0.029856 |
| which is closer to the results. The approximation is probably useful | <P>which is closer to the results. The approximation is probably useful |
| only for very small intervals and we don't have enough experience to | only for very small intervals and we don't have enough experience to |
| know if you will speed up the convergence or not. | know if you will speed up the convergence or not.<BR></P> |
| </pre> | </PRE><PRE> -ln(12)= -2.484 |
| <pre> -ln(12)= -2.484 | |
| -ln(6/1)=-ln(6)= -1.791 | -ln(6/1)=-ln(6)= -1.791 |
| -ln(3/1)=-ln(3)= -1.0986 | -ln(3/1)=-ln(3)= -1.0986 |
| -ln(12/6)=-ln(2)= -0.693 | -ln(12/6)=-ln(2)= -0.693 |
| </pre> | </PRE>In version 0.9 and higher you can still have valuable results even if your |
| stepm parameter is bigger than a month. The idea is to run with bigger stepm in | |
| <h4><font color="#FF0000">Guess values for computing variances</font></h4> | order to have a quicker convergence at the price of a small bias. Once you know |
| which model you want to fit, you can put stepm=1 and wait hours or days to get | |
| <p>This is an output if <a href="#mle">mle</a>=1. But it can be | the convergence! To get unbiased results even with large stepm we introduce the |
| used as an input to get the various output data files (Health | idea of pseudo likelihood by interpolating two exact likelihoods. In |
| expectancies, stationary prevalence etc.) and figures without | more detail: |
| rerunning the rather long maximisation phase (mle=0). </p> | <P>If the interval of <EM>d</EM> months between two waves is not a multiple of |
| 'stepm', but is between <EM>(n-1) stepm</EM> and <EM>n stepm</EM> then | |
| <p>The scales are small values for the evaluation of numerical | both exact likelihoods are computed (the contribution to the likelihood at <EM>n |
| derivatives. These derivatives are used to compute the hessian | stepm</EM> requires one matrix product more) (let us remember that we are |
| matrix of the parameters, that is the inverse of the covariance | modelling the probability to be observed in a particular state after <EM>d</EM> |
| matrix, and the variances of health expectancies. Each line | months being observed at a particular state at 0). The distance, (<EM>bh</EM> in |
| consists in indices "ij" followed by the initial scales | the program), from the month of interview to the rounded date of <EM>n |
| (zero to simplify) associated with aij and bij. </p> | stepm</EM> is computed. It can be negative (interview occurs before <EM>n |
| stepm</EM>) or positive if the interview occurs after <EM>n stepm</EM> (and | |
| <ul> | before <EM>(n+1)stepm</EM>). <BR>Then the final contribution to the total |
| <li>If mle=1 you can enter zeros:</li> | likelihood is a weighted average of these two exact likelihoods at <EM>n |
| <li><blockquote> | stepm</EM> (out) and at <EM>(n-1)stepm</EM>(savm). We did not want to compute |
| <pre># Scales (for hessian or gradient estimation) | the third likelihood at <EM>(n+1)stepm</EM> because it is too costly in time, so |
| we used an extrapolation if <EM>bh</EM> is positive. <BR>The formula | |
| for the inter/extrapolation may vary according to the value of parameter mle: <PRE>mle=1 lli= log((1.+bbh)*out[s1][s2]- bbh*savm[s1][s2]); /* linear interpolation */ | |
| mle=2 lli= (savm[s1][s2]>(double)1.e-8 ? \ | |
| log((1.+bbh)*out[s1][s2]- bbh*(savm[s1][s2])): \ | |
| log((1.+bbh)*out[s1][s2])); /* linear interpolation */ | |
| mle=3 lli= (savm[s1][s2]>1.e-8 ? \ | |
| (1.+bbh)*log(out[s1][s2])- bbh*log(savm[s1][s2]): \ | |
| log((1.+bbh)*out[s1][s2])); /* exponential inter-extrapolation */ | |
| mle=4 lli=log(out[s[mw[mi][i]][i]][s[mw[mi+1][i]][i]]); /* No interpolation */ | |
| no need to save previous likelihood into memory. | |
| </PRE> | |
| <P>If the death occurs between the first and second pass, and for example more | |
| precisely between <EM>n stepm</EM> and <EM>(n+1)stepm</EM> the contribution of | |
| these people to the likelihood is simply the difference between the probability | |
| of dying before <EM>n stepm</EM> and the probability of dying before | |
| <EM>(n+1)stepm</EM>. There was a bug in version 0.8 and death was treated as any | |
| other state, i.e. as if it was an observed death at second pass. This was not | |
| precise but correct, although when information on the precise month of | |
| death came (death occuring prior to second pass) we did not change the | |
| likelihood accordingly. We thank Chris Jackson for correcting it. In earlier | |
| versions (fortunately before first publication) the total mortality | |
| was thus overestimated (people were dying too early) by about 10%. Version | |
| 0.95 and higher are correct. | |
| <P>Our suggested choice is mle=1 . If stepm=1 there is no difference between | |
| various mle options (methods of interpolation). If stepm is big, like 12 or 24 | |
| or 48 and mle=4 (no interpolation) the bias may be very important if the mean | |
| duration between two waves is not a multiple of stepm. See the appendix in our | |
| main publication concerning the sine curve of biases. | |
| <H4><FONT color=#ff0000>Guess values for computing variances</FONT></H4> | |
| <P>These values are output by the maximisation of the likelihood <A | |
| href="http://euroreves.ined.fr/imach/doc/imach.htm#mle">mle</A>=1 and | |
| can be used as an input for a second run in order to get the various output data | |
| files (Health expectancies, period prevalence etc.) and figures without | |
| rerunning the long maximisation phase (mle=0). </P> | |
| <P>The 'scales' are small values needed for the computing of numerical | |
| derivatives. These derivatives are used to compute the hessian matrix of the | |
| parameters, that is the inverse of the covariance matrix. They are often used | |
| for estimating variances and confidence intervals. Each line consists of indices | |
| "ij" followed by the initial scales (zero to simplify) associated with aij and | |
| bij. </P> | |
| <UL> | |
| <LI>If mle=1 you can enter zeros: | |
| <LI> | |
| <BLOCKQUOTE><PRE># Scales (for hessian or gradient estimation) | |
| 12 0. 0. | 12 0. 0. |
| 13 0. 0. | 13 0. 0. |
| 21 0. 0. | 21 0. 0. |
| 23 0. 0. </pre> | 23 0. 0. </PRE></BLOCKQUOTE> |
| </blockquote> | <LI>If mle=0 (no maximisation of Likelihood) you must enter a covariance |
| </li> | matrix (usually obtained from an earlier run). </LI></UL> |
| <li>If mle=0 you must enter a covariance matrix (usually | <H4><FONT color=#ff0000>Covariance matrix of parameters</FONT></H4> |
| obtained from an earlier run).</li> | <P>The covariance matrix is output if <A |
| </ul> | href="http://euroreves.ined.fr/imach/doc/imach.htm#mle">mle</A>=1. But it can be |
| also be used as an input to get the various output data files (Health | |
| <h4><font color="#FF0000">Covariance matrix of parameters</font></h4> | expectancies, period prevalence etc.) and figures without rerunning |
| the maximisation phase (mle=0). <BR>Each line starts with indices | |
| <p>This is an output if <a href="#mle">mle</a>=1. But it can be | "ijk" followed by the covariances between aij and bij:<BR> |
| used as an input to get the various output data files (Health | </P><PRE> 121 Var(a12) |
| expectancies, stationary prevalence etc.) and figures without | |
| rerunning the rather long maximisation phase (mle=0). <br> | |
| Each line starts with indices "ijk" followed by the | |
| covariances between aij and bij:<br> | |
| </p> | |
| <pre> | |
| 121 Var(a12) | |
| 122 Cov(b12,a12) Var(b12) | 122 Cov(b12,a12) Var(b12) |
| ... | ... |
| 232 Cov(b23,a12) Cov(b23,b12) ... Var (b23) </pre> | 232 Cov(b23,a12) Cov(b23,b12) ... Var (b23) </PRE> |
| <UL> | |
| <ul> | <LI>If mle=1 you can enter zeros. |
| <li>If mle=1 you can enter zeros. </li> | <LI><PRE># Covariance matrix |
| <li><pre># Covariance matrix | |
| 121 0. | 121 0. |
| 122 0. 0. | 122 0. 0. |
| 131 0. 0. 0. | 131 0. 0. 0. |
| Line 538 covariances between aij and bij:<br> | Line 470 covariances between aij and bij:<br> |
| 211 0. 0. 0. 0. 0. | 211 0. 0. 0. 0. 0. |
| 212 0. 0. 0. 0. 0. 0. | 212 0. 0. 0. 0. 0. 0. |
| 231 0. 0. 0. 0. 0. 0. 0. | 231 0. 0. 0. 0. 0. 0. 0. |
| 232 0. 0. 0. 0. 0. 0. 0. 0.</pre> | 232 0. 0. 0. 0. 0. 0. 0. 0.</PRE> |
| </li> | <LI>If mle=0 you must enter a covariance matrix (usually obtained from an |
| <li>If mle=0 you must enter a covariance matrix (usually | earlier run). </LI></UL> |
| obtained from an earlier run). </li> | <H4><FONT color=#ff0000>Age range for calculation of stationary prevalences and |
| </ul> | health expectancies</FONT></H4><PRE>agemin=70 agemax=100 bage=50 fage=100</PRE> |
| <P>Once we obtained the estimated parameters, the program is able to calculate | |
| <h4><font color="#FF0000">Age range for calculation of stationary | period prevalence, transitions probabilities and life expectancies at any age. |
| prevalences and health expectancies</font></h4> | Choice of the age range is useful for extrapolation. In this example, |
| the age of people interviewed varies from 69 to 102 and the model is | |
| <pre>agemin=70 agemax=100 bage=50 fage=100</pre> | estimated using their exact ages. But if you are interested in the |
| age-specific period prevalence you can start the simulation at an | |
| <pre> | exact age like 70 and stop at 100. Then the program will draw at |
| Once we obtained the estimated parameters, the program is able | least two curves describing the forecasted prevalences of two cohorts, |
| to calculated stationary prevalence, transitions probabilities | one for healthy people at age 70 and the second for disabled people at |
| and life expectancies at any age. Choice of age range is useful | the same initial age. And according to the mixing property |
| for extrapolation. In our data file, ages varies from age 70 to | (ergodicity) and because of recovery, both prevalences will tend to be |
| 102. It is possible to get extrapolated stationary prevalence by | identical at later ages. Thus if you want to compute the prevalence at |
| age ranging from agemin to agemax. | age 70, you should enter a lower agemin value. |
| <P>Setting bage=50 (begin age) and fage=100 (final age), let the program compute | |
| life expectancy from age 'bage' to age 'fage'. As we use a model, we can | |
| Setting bage=50 (begin age) and fage=100 (final age), makes | interessingly compute life expectancy on a wider age range than the age range |
| the program computing life expectancy from age 'bage' to age | from the data. But the model can be rather wrong on much larger intervals. |
| 'fage'. As we use a model, we can interessingly compute life | Program is limited to around 120 for upper age! <PRE></PRE> |
| expectancy on a wider age range than the age range from the data. | <UL> |
| But the model can be rather wrong on much larger intervals. | <LI><B>agemin=</B> Minimum age for calculation of the period prevalence |
| Program is limited to around 120 for upper age! | <LI><B>agemax=</B> Maximum age for calculation of the period prevalence |
| </pre> | <LI><B>bage=</B> Minimum age for calculation of the health expectancies |
| <LI><B>fage=</B> Maximum age for calculation of the health expectancies | |
| <ul> | </LI></UL> |
| <li><b>agemin=</b> Minimum age for calculation of the | <H4><A name=Computing><FONT color=#ff0000>Computing</FONT></A><FONT |
| stationary prevalence </li> | color=#ff0000> the cross-sectional prevalence</FONT></H4><PRE>begin-prev-date=1/1/1984 end-prev-date=1/6/1988 estepm=1</PRE> |
| <li><b>agemax=</b> Maximum age for calculation of the | <P>Statements 'begin-prev-date' and 'end-prev-date' allow the user to |
| stationary prevalence </li> | select the period in which the observed prevalences in each state. In |
| <li><b>bage=</b> Minimum age for calculation of the health | this example, the prevalences are calculated on data survey collected |
| expectancies </li> | between 1 January 1984 and 1 June 1988. </P> |
| <li><b>fage=</b> Maximum age for calculation of the health | <UL> |
| expectancies </li> | <LI><STRONG>begin-prev-date= </STRONG>Starting date (day/month/year) |
| </ul> | <LI><STRONG>end-prev-date= </STRONG>Final date (day/month/year) |
| <LI><STRONG>estepm= </STRONG>Unit (in months).We compute the life expectancy | |
| <h4><a name="Computing"><font color="#FF0000">Computing</font></a><font | from trapezoids spaced every estepm months. This is mainly to measure the |
| color="#FF0000"> the observed prevalence</font></h4> | difference between two models: for example if stepm=24 months pijx are given |
| only every 2 years and by summing them we are calculating an estimate of the | |
| <pre>begin-prev-date=1/1/1984 end-prev-date=1/6/1988 estepm=1</pre> | Life Expectancy assuming a linear progression inbetween and thus |
| overestimating or underestimating according to the curvature of the survival | |
| <pre> | function. If, for the same date, we estimate the model with stepm=1 month, we |
| Statements 'begin-prev-date' and 'end-prev-date' allow to | can keep estepm to 24 months to compare the new estimate of Life expectancy |
| select the period in which we calculate the observed prevalences | with the same linear hypothesis. A more precise result, taking into account a |
| in each state. In this example, the prevalences are calculated on | more precise curvature will be obtained if estepm is as small as stepm. |
| data survey collected between 1 january 1984 and 1 june 1988. | </LI></UL> |
| </pre> | <H4><FONT color=#ff0000>Population- or status-based health |
| expectancies</FONT></H4><PRE>pop_based=0</PRE> | |
| <ul> | <P>The program computes status-based health expectancies, i.e health |
| <li><strong>begin-prev-date= </strong>Starting date | expectancies which depend on the initial health state. If you are healthy, your |
| (day/month/year)</li> | healthy life expectancy (e11) is higher than if you were disabled (e21, with e11 |
| <li><strong>end-prev-date= </strong>Final date | > e21).<BR>To compute a healthy life expectancy 'independent' of the initial |
| (day/month/year)</li> | status we have to weight e11 and e21 according to the probability of |
| <li><strong>estepm= </strong>Unit (in months).We compute the | being in each state at initial age which correspond to the proportions |
| life expectancy from trapezoids spaced every estepm | of people in each health state (cross-sectional prevalences). |
| months. This is mainly to measure the difference between | <P>We could also compute e12 and e12 and get e.2 by weighting them according to |
| two models: for example if stepm=24 months pijx are given | the observed cross-sectional prevalences at initial age. |
| only every 2 years and by summing them we are calculating | <P>In a similar way we could compute the total life expectancy by summing e.1 |
| an estimate of the Life Expectancy assuming a linear | and e.2 . <BR>The main difference between 'population based' and 'implied' or |
| progression inbetween and thus overestimating or | 'period' is in the weights used. 'Usually', cross-sectional prevalences of |
| underestimating according to the curvature of the | disability are higher than period prevalences particularly at old ages. This is |
| survival function. If, for the same date, we estimate the | true if the country is improving its health system by teaching people how to |
| model with stepm=1 month, we can keep estepm to 24 months | prevent disability by promoting better screening, for example of people |
| to compare the new estimate of Life expectancy with the | needing cataract surgery. Then the proportion of disabled people at |
| same linear hypothesis. A more precise result, taking | age 90 will be lower than the current observed proportion. |
| into account a more precise curvature will be obtained if | <P>Thus a better Health Expectancy and even a better Life Expectancy value is |
| estepm is as small as stepm.</li> | given by forecasting not only the current lower mortality at all ages but also a |
| </ul> | lower incidence of disability and higher recovery. <BR>Using the period |
| prevalences as weight instead of the cross-sectional prevalences we are | |
| <h4><font color="#FF0000">Population- or status-based health | computing indices which are more specific to the current situations and |
| expectancies</font></h4> | therefore more useful to predict improvements or regressions in the future as to |
| compare different policies in various countries. | |
| <pre>pop_based=0</pre> | <UL> |
| <LI><STRONG>popbased= 0 </STRONG>Health expectancies are computed at each age | |
| <p>The program computes status-based health expectancies, i.e | from period prevalences 'expected' at this initial age. |
| health expectancies which depends on your initial health state. | <LI><STRONG>popbased= 1 </STRONG>Health expectancies are computed at each age |
| If you are healthy your healthy life expectancy (e11) is higher | from cross-sectional 'observed' prevalence at the initial age. As all the |
| than if you were disabled (e21, with e11 > e21).<br> | population is not observed at the same exact date we define a short period |
| To compute a healthy life expectancy independant of the initial | where the observed prevalence can be computed as follows:<BR>we simply sum all people |
| status we have to weight e11 and e21 according to the probability | surveyed within these two exact dates who belong to a particular age group |
| to be in each state at initial age or, with other word, according | (single year) at the date of interview and are in a particular health state. |
| to the proportion of people in each state.<br> | Then it is easy to get the proportion of people in a particular |
| We prefer computing a 'pure' period healthy life expectancy based | health state as a percentage of all people of the same age group.<BR>If both dates are spaced and are |
| only on the transtion forces. Then the weights are simply the | covering two waves or more, people being interviewed twice or more are counted |
| stationnary prevalences or 'implied' prevalences at the initial | twice or more. The program takes into account the selection of individuals |
| age.<br> | interviewed between firstpass and lastpass too (we don't know if |
| Some other people would like to use the cross-sectional | this is useful). </LI></UL> |
| prevalences (the "Sullivan prevalences") observed at | <H4><FONT color=#ff0000>Prevalence forecasting (Experimental)</FONT></H4><PRE>starting-proj-date=1/1/1989 final-proj-date=1/1/1992 mov_average=0 </PRE> |
| the initial age during a period of time <a href="#Computing">defined | <P>Prevalence and population projections are only available if the interpolation |
| just above</a>. <br> | unit is a month, i.e. stepm=1 and if there are no covariate. The programme |
| </p> | estimates the prevalence in each state at a precise date expressed in |
| day/month/year. The programme computes one forecasted prevalence a year from a | |
| <ul> | starting date (1 January 1989 in this example) to a final date (1 January |
| <li><strong>popbased= 0 </strong>Health expectancies are | 1992). The statement mov_average allows computation of smoothed forecasted |
| computed at each age from stationary prevalences | prevalences with a five-age moving average centered at the mid-age of the |
| 'expected' at this initial age.</li> | fiveyear-age period. <BR></P> |
| <li><strong>popbased= 1 </strong>Health expectancies are | <H4><FONT color=#ff0000>Population forecasting (Experimental)</FONT></H4> |
| computed at each age from cross-sectional 'observed' | <UL> |
| prevalence at this initial age. As all the population is | <LI><STRONG>starting-proj-date</STRONG>= starting date (day/month/year) of |
| not observed at the same exact date we define a short | forecasting |
| period were the observed prevalence is computed.</li> | <LI><STRONG>final-proj-date= </STRONG>final date (day/month/year) of |
| </ul> | forecasting |
| <LI><STRONG>mov_average</STRONG>= smoothing with a five-age moving average | |
| <h4><font color="#FF0000">Prevalence forecasting ( Experimental)</font></h4> | centered at the mid-age of the fiveyear-age period. The command<STRONG> |
| mov_average</STRONG> takes value 1 if the prevalences are smoothed and 0 | |
| <pre>starting-proj-date=1/1/1989 final-proj-date=1/1/1992 mov_average=0 </pre> | otherwise. </LI></UL> |
| <UL type=disc> | |
| <p>Prevalence and population projections are only available if | <LI><B>popforecast= 0 </B>Option for population forecasting. If popforecast=1, |
| the interpolation unit is a month, i.e. stepm=1 and if there are | the programme does the forecasting<B>.</B> |
| no covariate. The programme estimates the prevalence in each | <LI><B>popfile= </B>name of the population file |
| state at a precise date expressed in day/month/year. The | <LI><B>popfiledate=</B> date of the population population |
| programme computes one forecasted prevalence a year from a | <LI><B>last-popfiledate</B>= date of the last population projection |
| starting date (1 january of 1989 in this example) to a final date | </LI></UL> |
| (1 january 1992). The statement mov_average allows to compute | <HR> |
| smoothed forecasted prevalences with a five-age moving average | |
| centered at the mid-age of the five-age period. <br> | <H2><A name=running></A><FONT color=#00006a>Running Imach with this |
| </p> | example</FONT></H2> |
| <P>We assume that you have already typed your <A | |
| <ul> | href="http://euroreves.ined.fr/imach/doc/biaspar.imach">1st_example parameter |
| <li><strong>starting-proj-date</strong>= starting date | file</A> as explained <A |
| (day/month/year) of forecasting</li> | href="http://euroreves.ined.fr/imach/doc/imach.htm#biaspar">above</A>. To run |
| <li><strong>final-proj-date= </strong>final date | the program under Windows you should either: </P> |
| (day/month/year) of forecasting</li> | <UL> |
| <li><strong>mov_average</strong>= smoothing with a five-age | <LI>click on the imach.exe icon and either: |
| moving average centered at the mid-age of the five-age | <UL> |
| period. The command<strong> mov_average</strong> takes | <LI>enter the name of the parameter file which is for example |
| value 1 if the prevalences are smoothed and 0 otherwise.</li> | <TT>C:\home\myname\lsoa\biaspar.imach</TT> |
| </ul> | <LI>or locate the biaspar.imach icon in your folder such as |
| <TT>C:\home\myname\lsoa</TT> and drag it, with your mouse, on the already | |
| <h4><font color="#FF0000">Last uncommented line : Population | open imach window. </LI></UL> |
| forecasting </font></h4> | <LI>With version (0.97b) if you ran setup at installation, Windows is supposed |
| to understand the ".imach" extension and you can right click the biaspar.imach | |
| <pre>popforecast=0 popfile=pyram.txt popfiledate=1/1/1989 last-popfiledate=1/1/1992</pre> | icon and either edit with wordpad (better than notepad) the parameter file or |
| execute it with IMaCh. </LI></UL> | |
| <p>This command is available if the interpolation unit is a | <P>The time to converge depends on the step unit used (1 month is more |
| month, i.e. stepm=1 and if popforecast=1. From a data file | precise but more cpu time consuming), on the number of cases, and on the number of |
| including age and number of persons alive at the precise date | variables (covariates). |
| ‘popfiledate’, you can forecast the number of persons | <P>The program outputs many files. Most of them are files which will be plotted |
| in each state until date ‘last-popfiledate’. In this | for better understanding. </P>To run under Linux is mostly the same. |
| example, the popfile <a href="pyram.txt"><b>pyram.txt</b></a> | <P>It is no more difficult to run IMaCh on a MacIntosh. |
| includes real data which are the Japanese population in 1989.<br> | <HR> |
| </p> | |
| <H2><A name=output><FONT color=#00006a>Output of the program and graphs</FONT> | |
| <ul type="disc"> | </A></H2> |
| <li class="MsoNormal" | <P>Once the optimization is finished (once the convergence is reached), many |
| style="TEXT-ALIGN: justify; mso-margin-top-alt: auto; mso-margin-bottom-alt: auto; mso-list: l10 level1 lfo36; tab-stops: list 36.0pt"><b>popforecast= | tables and graphics are produced. |
| 0 </b>Option for population forecasting. If | <P>The IMaCh program will create a subdirectory with the same name as your |
| popforecast=1, the programme does the forecasting<b>.</b></li> | parameter file (here mypar) where all the tables and figures will be |
| <li class="MsoNormal" | stored.<BR>Important files like the log file and the output parameter file |
| style="TEXT-ALIGN: justify; mso-margin-top-alt: auto; mso-margin-bottom-alt: auto; mso-list: l10 level1 lfo36; tab-stops: list 36.0pt"><b>popfile= | (the latter contains the maximum likelihood estimates) are stored at |
| </b>name of the population file</li> | the main level not in this subdirectory. Files with extension .log and |
| <li class="MsoNormal" | .txt can be edited with a standard editor like wordpad or notepad or |
| style="TEXT-ALIGN: justify; mso-margin-top-alt: auto; mso-margin-bottom-alt: auto; mso-list: l10 level1 lfo36; tab-stops: list 36.0pt"><b>popfiledate=</b> | even can be viewed with a browser like Internet Explorer or Mozilla. |
| date of the population population</li> | <P>The main html file is also named with the same name <A |
| <li class="MsoNormal" | href="http://euroreves.ined.fr/imach/doc/biaspar.htm">biaspar.htm</A>. You can |
| style="TEXT-ALIGN: justify; mso-margin-top-alt: auto; mso-margin-bottom-alt: auto; mso-list: l10 level1 lfo36; tab-stops: list 36.0pt"><b>last-popfiledate</b>= | click on it by holding your shift key in order to open it in another window |
| date of the last population projection </li> | (Windows). |
| </ul> | <P>Our grapher is Gnuplot, an interactive plotting program (GPL) which can |
| also work in batch mode. A gnuplot reference manual is available <A | |
| <hr> | href="http://www.gnuplot.info/">here</A>. <BR>When the run is finished, and in |
| order that the window doesn't disappear, the user should enter a character like | |
| <h2><a name="running"></a><font color="#00006A">Running Imach | <TT>q</TT> for quitting. <BR>These characters are:<BR></P> |
| with this example</font></h2> | <UL> |
| <LI>'e' for opening the main result html file <A | |
| <pre>We assume that you typed in your <a href="biaspar.imach">1st_example | href="http://euroreves.ined.fr/imach/doc/biaspar.htm"><STRONG>biaspar.htm</STRONG></A> |
| parameter file</a> as explained <a href="#biaspar">above</a>. | file to edit the output files and graphs. |
| <LI>'g' to graph again | |
| To run the program you should either: | <LI>'c' to start again the program from the beginning. |
| </pre> | <LI>'q' for exiting. </LI></UL>The main gnuplot file is named |
| <TT>biaspar.gp</TT> and can be edited (right click) and run again. | |
| <ul> | <P>Gnuplot is easy and you can use it to make more complex graphs. Just click on |
| <li>click on the imach.exe icon and enter the name of the | gnuplot and type plot sin(x) to see how easy it is. |
| parameter file which is for example <a | <H5><FONT size=4><STRONG>Results files </STRONG></FONT><BR><BR><FONT |
| href="C:\usr\imach\mle\biaspar.imach">C:\usr\imach\mle\biaspar.imach</a> | color=#ec5e5e size=3><STRONG>- </STRONG></FONT><A |
| </li> | name="cross-sectional prevalence in each state"><FONT color=#ec5e5e |
| <li>You also can locate the biaspar.imach icon in <a | size=3><STRONG>cross-sectional prevalence in each state</STRONG></FONT></A><FONT |
| href="C:\usr\imach\mle">C:\usr\imach\mle</a> with your | color=#ec5e5e size=3><STRONG> (and at first pass)</STRONG></FONT><B>: </B><A |
| mouse and drag it with the mouse on the imach window). </li> | href="http://euroreves.ined.fr/imach/doc/biaspar/prbiaspar.txt"><B>biaspar/prbiaspar.txt</B></A><BR></H5> |
| <li>With latest version (0.7 and higher) if you setup windows | <P>The first line is the title and displays each field of the file. First column |
| in order to understand ".imach" extension you | corresponds to age. Fields 2 and 6 are the proportion of individuals in states 1 |
| can right click the biaspar.imach icon and either edit | and 2 respectively as observed at first exam. Others fields are the numbers of |
| with notepad the parameter file or execute it with imach | people in states 1, 2 or more. The number of columns increases if the number of |
| or whatever. </li> | states is higher than 2.<BR>The header of the file is </P><PRE># Age Prev(1) N(1) N Age Prev(2) N(2) N |
| </ul> | |
| <pre>The time to converge depends on the step unit that you used (1 | |
| month is cpu consuming), on the number of cases, and on the | |
| number of variables. | |
| The program outputs many files. Most of them are files which | |
| will be plotted for better understanding. | |
| </pre> | |
| <hr> | |
| <h2><a name="output"><font color="#00006A">Output of the program | |
| and graphs</font> </a></h2> | |
| <p>Once the optimization is finished, some graphics can be made | |
| with a grapher. We use Gnuplot which is an interactive plotting | |
| program copyrighted but freely distributed. A gnuplot reference | |
| manual is available <a href="http://www.gnuplot.info/">here</a>. <br> | |
| When the running is finished, the user should enter a caracter | |
| for plotting and output editing. <br> | |
| These caracters are:<br> | |
| </p> | |
| <ul> | |
| <li>'c' to start again the program from the beginning.</li> | |
| <li>'e' opens the <a href="biaspar.htm"><strong>biaspar.htm</strong></a> | |
| file to edit the output files and graphs. </li> | |
| <li>'g' to graph again</li> | |
| <li>'q' for exiting.</li> | |
| </ul> | |
| <h5><font size="4"><strong>Results files </strong></font><br> | |
| <br> | |
| <font color="#EC5E5E" size="3"><strong>- </strong></font><a | |
| name="Observed prevalence in each state"><font color="#EC5E5E" | |
| size="3"><strong>Observed prevalence in each state</strong></font></a><font | |
| color="#EC5E5E" size="3"><strong> (and at first pass)</strong></font><b>: | |
| </b><a href="prbiaspar.txt"><b>prbiaspar.txt</b></a><br> | |
| </h5> | |
| <p>The first line is the title and displays each field of the | |
| file. The first column is age. The fields 2 and 6 are the | |
| proportion of individuals in states 1 and 2 respectively as | |
| observed during the first exam. Others fields are the numbers of | |
| people in states 1, 2 or more. The number of columns increases if | |
| the number of states is higher than 2.<br> | |
| The header of the file is </p> | |
| <pre># Age Prev(1) N(1) N Age Prev(2) N(2) N | |
| 70 1.00000 631 631 70 0.00000 0 631 | 70 1.00000 631 631 70 0.00000 0 631 |
| 71 0.99681 625 627 71 0.00319 2 627 | 71 0.99681 625 627 71 0.00319 2 627 |
| 72 0.97125 1115 1148 72 0.02875 33 1148 </pre> | 72 0.97125 1115 1148 72 0.02875 33 1148 </PRE> |
| <P>It means that at age 70 (between 70 and 71), the prevalence in state 1 is | |
| <p>It means that at age 70, the prevalence in state 1 is 1.000 | 1.000 and in state 2 is 0.00 . At age 71 the number of individuals in state 1 is |
| and in state 2 is 0.00 . At age 71 the number of individuals in | 625 and in state 2 is 2, hence the total number of people aged 71 is 625+2=627. |
| state 1 is 625 and in state 2 is 2, hence the total number of | <BR></P> |
| people aged 71 is 625+2=627. <br> | <H5><FONT color=#ec5e5e size=3><B>- Estimated parameters and covariance |
| </p> | matrix</B></FONT><B>: </B><A |
| href="http://euroreves.ined.fr/imach/doc/rbiaspar.txt"><B>rbiaspar.imach</B></A></H5> | |
| <h5><font color="#EC5E5E" size="3"><b>- Estimated parameters and | <P>This file contains all the maximisation results: </P><PRE> -2 log likelihood= 21660.918613445392 |
| covariance matrix</b></font><b>: </b><a href="rbiaspar.txt"><b>rbiaspar.imach</b></a></h5> | |
| <p>This file contains all the maximisation results: </p> | |
| <pre> -2 log likelihood= 21660.918613445392 | |
| Estimated parameters: a12 = -12.290174 b12 = 0.092161 | Estimated parameters: a12 = -12.290174 b12 = 0.092161 |
| a13 = -9.155590 b13 = 0.046627 | a13 = -9.155590 b13 = 0.046627 |
| a21 = -2.629849 b21 = -0.022030 | a21 = -2.629849 b21 = -0.022030 |
| Line 804 covariance matrix</b></font><b>: </b><a | Line 679 covariance matrix</b></font><b>: </b><a |
| Var(b21) = 1.29229e-004 | Var(b21) = 1.29229e-004 |
| Var(a23) = 4.48405e-001 | Var(a23) = 4.48405e-001 |
| Var(b23) = 5.85631e-005 | Var(b23) = 5.85631e-005 |
| </pre> | </PRE> |
| <P>By substitution of these parameters in the regression model, we obtain the | |
| <p>By substitution of these parameters in the regression model, | elementary transition probabilities:</P> |
| we obtain the elementary transition probabilities:</p> | <P><IMG height=300 |
| src="Computing Health Expectancies using IMaCh_fichiers/pebiaspar11.png" | |
| <p><img src="pebiaspar1.gif" width="400" height="300"></p> | width=400></P> |
| <H5><FONT color=#ec5e5e size=3><B>- Transition probabilities</B></FONT><B>: | |
| <h5><font color="#EC5E5E" size="3"><b>- Transition probabilities</b></font><b>: | </B><A |
| </b><a href="pijrbiaspar.txt"><b>pijrbiaspar.txt</b></a></h5> | href="http://euroreves.ined.fr/imach/doc/biaspar/pijrbiaspar.txt"><B>biaspar/pijrbiaspar.txt</B></A></H5> |
| <P>Here are the transitions probabilities Pij(x, x+nh). The second column is the | |
| <p>Here are the transitions probabilities Pij(x, x+nh) where nh | starting age x (from age 95 to 65), the third is age (x+nh) and the others are |
| is a multiple of 2 years. The first column is the starting age x | the transition probabilities p11, p12, p13, p21, p22, p23. The first column |
| (from age 50 to 100), the second is age (x+nh) and the others are | indicates the value of the covariate (without any other variable than age it is |
| the transition probabilities p11, p12, p13, p21, p22, p23. For | equal to 1) For example, line 5 of the file is: </P><PRE>1 100 106 0.02655 0.17622 0.79722 0.01809 0.13678 0.84513 </PRE> |
| example, line 5 of the file is: </p> | <P>and this means: </P><PRE>p11(100,106)=0.02655 |
| <pre> 100 106 0.02655 0.17622 0.79722 0.01809 0.13678 0.84513 </pre> | |
| <p>and this means: </p> | |
| <pre>p11(100,106)=0.02655 | |
| p12(100,106)=0.17622 | p12(100,106)=0.17622 |
| p13(100,106)=0.79722 | p13(100,106)=0.79722 |
| p21(100,106)=0.01809 | p21(100,106)=0.01809 |
| p22(100,106)=0.13678 | p22(100,106)=0.13678 |
| p22(100,106)=0.84513 </pre> | p22(100,106)=0.84513 </PRE> |
| <H5><FONT color=#ec5e5e size=3><B>- </B></FONT><A | |
| <h5><font color="#EC5E5E" size="3"><b>- </b></font><a | name="Period prevalence in each state"><FONT color=#ec5e5e size=3><B>Period |
| name="Stationary prevalence in each state"><font color="#EC5E5E" | prevalence in each state</B></FONT></A><B>: </B><A |
| size="3"><b>Stationary prevalence in each state</b></font></a><b>: | href="http://euroreves.ined.fr/imach/doc/biaspar/plrbiaspar.txt"><B>biaspar/plrbiaspar.txt</B></A></H5><PRE>#Prevalence |
| </b><a href="plrbiaspar.txt"><b>plrbiaspar.txt</b></a></h5> | |
| <pre>#Prevalence | |
| #Age 1-1 2-2 | #Age 1-1 2-2 |
| #************ | #************ |
| 70 0.90134 0.09866 | 70 0.90134 0.09866 |
| 71 0.89177 0.10823 | 71 0.89177 0.10823 |
| 72 0.88139 0.11861 | 72 0.88139 0.11861 |
| 73 0.87015 0.12985 </pre> | 73 0.87015 0.12985 </PRE> |
| <P>At age 70 the period prevalence is 0.90134 in state 1 and 0.09866 in state 2. | |
| <p>At age 70 the stationary prevalence is 0.90134 in state 1 and | This period prevalence differs from the cross-sectional prevalence and |
| 0.09866 in state 2. This stationary prevalence differs from | we explaining. The cross-sectional prevalence at age 70 results from |
| observed prevalence. Here is the point. The observed prevalence | the incidence of disability, incidence of recovery and mortality which |
| at age 70 results from the incidence of disability, incidence of | occurred in the past for the cohort. Period prevalence results from a |
| recovery and mortality which occurred in the past of the cohort. | simulation with current incidences of disability, recovery and |
| Stationary prevalence results from a simulation with actual | mortality estimated from this cross-longitudinal survey. It is a good |
| incidences and mortality (estimated from this cross-longitudinal | prediction of the prevalence in the future if "nothing changes in the |
| survey). It is the best predictive value of the prevalence in the | future". This is exactly what demographers do with a period life |
| future if "nothing changes in the future". This is | table. Life expectancy is the expected mean survival time if current |
| exactly what demographers do with a Life table. Life expectancy | mortality rates (age-specific incidences of mortality) "remain |
| is the expected mean time to survive if observed mortality rates | constant" in the future. |
| (incidence of mortality) "remains constant" in the | </P> |
| future. </p> | <H5><FONT color=#ec5e5e size=3><B>- Standard deviation of period |
| prevalence</B></FONT><B>: </B><A | |
| <h5><font color="#EC5E5E" size="3"><b>- Standard deviation of | href="http://euroreves.ined.fr/imach/doc/biaspar/vplrbiaspar.txt"><B>biaspar/vplrbiaspar.txt</B></A></H5> |
| stationary prevalence</b></font><b>: </b><a | <P>The period prevalence has to be compared with the cross-sectional prevalence. |
| href="vplrbiaspar.txt"><b>vplrbiaspar.txt</b></a></h5> | But both are statistical estimates and therefore have confidence intervals. |
| <BR>For the cross-sectional prevalence we generally need information on the | |
| <p>The stationary prevalence has to be compared with the observed | design of the surveys. It is usually not enough to consider the number of people |
| prevalence by age. But both are statistical estimates and | surveyed at a particular age and to estimate a Bernouilli confidence interval |
| subjected to stochastic errors due to the size of the sample, the | based on the prevalence at that age. But you can do it to have an idea of the |
| design of the survey, and, for the stationary prevalence to the | randomness. At least you can get a visual appreciation of the randomness by |
| model used and fitted. It is possible to compute the standard | looking at the fluctuation over ages. |
| deviation of the stationary prevalence at each age.</p> | <P>For the period prevalence it is possible to estimate the confidence interval |
| from the Hessian matrix (see the publication for details). We are supposing that | |
| <h5><font color="#EC5E5E" size="3">-Observed and stationary | the design of the survey will only alter the weight of each individual. IMaCh |
| prevalence in state (2=disable) with confidence interval</font>:<b> | scales the weights of individuals-waves contributing to the likelihood by |
| </b><a href="vbiaspar21.htm"><b>vbiaspar21.gif</b></a></h5> | making the sum of the weights equal to the sum of individuals-waves |
| contributing: a weighted survey doesn't increase or decrease the size of the | |
| <p>This graph exhibits the stationary prevalence in state (2) | survey, it only give more weight to some individuals and thus less to the |
| with the confidence interval in red. The green curve is the | others. |
| observed prevalence (or proportion of individuals in state (2)). | <H5><FONT color=#ec5e5e size=3>-cross-sectional and period prevalence in state |
| Without discussing the results (it is not the purpose here), we | (2=disable) with confidence interval</FONT>:<B> </B><A |
| observe that the green curve is rather below the stationary | href="http://euroreves.ined.fr/imach/doc/biaspar/vbiaspar21.htm"><B>biaspar/vbiaspar21.png</B></A></H5> |
| prevalence. It suggests an increase of the disability prevalence | <P>This graph exhibits the period prevalence in state (2) with the confidence |
| in the future.</p> | interval in red. The green curve is the observed prevalence (or proportion of |
| individuals in state (2)). Without discussing the results (it is not the purpose | |
| <p><img src="vbiaspar21.gif" width="400" height="300"></p> | here), we observe that the green curve is somewhat below the period |
| prevalence. If the data were not biased by the non inclusion of people | |
| <h5><font color="#EC5E5E" size="3"><b>-Convergence to the | living in institutions we would have concluded that the prevalence of |
| stationary prevalence of disability</b></font><b>: </b><a | disability will increase in the future (see the main publication if |
| href="pbiaspar11.gif"><b>pbiaspar11.gif</b></a><br> | you are interested in real data and results which are opposite).</P> |
| <img src="pbiaspar11.gif" width="400" height="300"> </h5> | <P><IMG height=300 |
| src="Computing Health Expectancies using IMaCh_fichiers/vbiaspar21.png" | |
| <p>This graph plots the conditional transition probabilities from | width=400></P> |
| an initial state (1=healthy in red at the bottom, or 2=disable in | <H5><FONT color=#ec5e5e size=3><B>-Convergence to the period prevalence of |
| green on top) at age <em>x </em>to the final state 2=disable<em> </em>at | disability</B></FONT><B>: </B><A |
| age <em>x+h. </em>Conditional means at the condition to be alive | href="Computing Health Expectancies using IMaCh_fichiers/pbiaspar11.png"><B>biaspar/pbiaspar11.png</B></A><BR><IMG |
| at age <em>x+h </em>which is <i>hP12x</i> + <em>hP22x</em>. The | height=300 |
| curves <i>hP12x/(hP12x</i> + <em>hP22x) </em>and <i>hP22x/(hP12x</i> | src="Computing Health Expectancies using IMaCh_fichiers/pbiaspar11.png" |
| + <em>hP22x) </em>converge with <em>h, </em>to the <em>stationary | width=400> </H5> |
| prevalence of disability</em>. In order to get the stationary | <P>This graph plots the conditional transition probabilities from an initial |
| prevalence at age 70 we should start the process at an earlier | state (1=healthy in red at the bottom, or 2=disabled in green on the top) at age |
| age, i.e.50. If the disability state is defined by severe | <EM>x </EM>to the final state 2=disabled<EM> </EM>at age <EM>x+h |
| disability criteria with only a few chance to recover, then the | </EM> where conditional means conditional on being alive at age <EM>x+h </EM>which is |
| incidence of recovery is low and the time to convergence is | <I>hP12x</I> + <EM>hP22x</EM>. The curves <I>hP12x/(hP12x</I> + <EM>hP22x) |
| probably longer. But we don't have experience yet.</p> | </EM>and <I>hP22x/(hP12x</I> + <EM>hP22x) </EM>converge with <EM>h, </EM>to the |
| <EM>period prevalence of disability</EM>. In order to get the period prevalence | |
| <h5><font color="#EC5E5E" size="3"><b>- Life expectancies by age | at age 70 we should start the process at an earlier age, i.e.50. If the |
| and initial health status with standard deviation</b></font><b>: </b><a | disability state is defined by severe disability criteria with only a |
| href="erbiaspar.txt"><b>erbiaspar.txt</b></a></h5> | small chance of recovering, then the incidence of recovery is low and the time to convergence is |
| probably longer. But we don't have experience of this yet.</P> | |
| <pre># Health expectancies | <H5><FONT color=#ec5e5e size=3><B>- Life expectancies by age and initial health |
| status with standard deviation</B></FONT><B>: </B><A | |
| href="http://euroreves.ined.fr/imach/doc/biaspar/erbiaspar.txt"><B>biaspar/erbiaspar.txt</B></A></H5><PRE># Health expectancies | |
| # Age 1-1 (SE) 1-2 (SE) 2-1 (SE) 2-2 (SE) | # Age 1-1 (SE) 1-2 (SE) 2-1 (SE) 2-2 (SE) |
| 70 10.4171 (0.1517) 3.0433 (0.4733) 5.6641 (0.1121) 5.6907 (0.3366) | 70 11.0180 (0.1277) 3.1950 (0.3635) 4.6500 (0.0871) 4.4807 (0.2187) |
| 71 9.9325 (0.1409) 3.0495 (0.4234) 5.2627 (0.1107) 5.6384 (0.3129) | 71 10.4786 (0.1184) 3.2093 (0.3212) 4.3384 (0.0875) 4.4820 (0.2076) |
| 72 9.4603 (0.1319) 3.0540 (0.3770) 4.8810 (0.1099) 5.5811 (0.2907) | 72 9.9551 (0.1103) 3.2236 (0.2827) 4.0426 (0.0885) 4.4827 (0.1966) |
| 73 9.0009 (0.1246) 3.0565 (0.3345) 4.5188 (0.1098) 5.5187 (0.2702) | 73 9.4476 (0.1035) 3.2379 (0.2478) 3.7621 (0.0899) 4.4825 (0.1858) |
| </pre> | 74 8.9564 (0.0980) 3.2522 (0.2165) 3.4966 (0.0920) 4.4815 (0.1754) |
| 75 8.4815 (0.0937) 3.2665 (0.1887) 3.2457 (0.0946) 4.4798 (0.1656) | |
| <pre>For example 70 10.4171 (0.1517) 3.0433 (0.4733) 5.6641 (0.1121) 5.6907 (0.3366) means: | 76 8.0230 (0.0905) 3.2806 (0.1645) 3.0090 (0.0979) 4.4772 (0.1565) |
| e11=10.4171 e12=3.0433 e21=5.6641 e22=5.6907 </pre> | 77 7.5810 (0.0884) 3.2946 (0.1438) 2.7860 (0.1017) 4.4738 (0.1484) |
| 78 7.1554 (0.0871) 3.3084 (0.1264) 2.5763 (0.1062) 4.4696 (0.1416) | |
| <pre><img src="expbiaspar21.gif" width="400" height="300"><img | 79 6.7464 (0.0867) 3.3220 (0.1124) 2.3794 (0.1112) 4.4646 (0.1364) |
| src="expbiaspar11.gif" width="400" height="300"></pre> | 80 6.3538 (0.0868) 3.3354 (0.1014) 2.1949 (0.1168) 4.4587 (0.1331) |
| 81 5.9775 (0.0873) 3.3484 (0.0933) 2.0222 (0.1230) 4.4520 (0.1320) | |
| <p>For example, life expectancy of a healthy individual at age 70 | </PRE><PRE>For example 70 11.0180 (0.1277) 3.1950 (0.3635) 4.6500 (0.0871) 4.4807 (0.2187) |
| is 10.42 in the healthy state and 3.04 in the disability state | means |
| (=13.46 years). If he was disable at age 70, his life expectancy | e11=11.0180 e12=3.1950 e21=4.6500 e22=4.4807 </PRE><PRE><IMG height=300 src="Computing Health Expectancies using IMaCh_fichiers/expbiaspar21.png" width=400><IMG height=300 src="Computing Health Expectancies using IMaCh_fichiers/expbiaspar11.png" width=400></PRE> |
| will be shorter, 5.66 in the healthy state and 5.69 in the | <P>For example, life expectancy of a healthy individual at age 70 is 11.0 in the |
| disability state (=11.35 years). The total life expectancy is a | healthy state and 3.2 in the disability state (total of 14.2 years). If he was |
| weighted mean of both, 13.46 and 11.35; weight is the proportion | disabled at age 70, his life expectancy will be shorter, 4.65 years in the |
| of people disabled at age 70. In order to get a pure period index | healthy state and 4.5 in the disability state (=9.15 years). The total life |
| (i.e. based only on incidences) we use the <a | expectancy is a weighted mean of both, 14.2 and 9.15. The weight is the |
| href="#Stationary prevalence in each state">computed or | proportion of people disabled at age 70. In order to get a period index (i.e. |
| stationary prevalence</a> at age 70 (i.e. computed from | based only on incidences) we use the <A |
| incidences at earlier ages) instead of the <a | href="http://euroreves.ined.fr/imach/doc/imach.htm#Period prevalence in each state">stable |
| href="#Observed prevalence in each state">observed prevalence</a> | or period prevalence</A> at age 70 (i.e. computed from incidences at earlier |
| (for example at first exam) (<a href="#Health expectancies">see | ages) instead of the <A |
| below</a>).</p> | href="http://euroreves.ined.fr/imach/doc/imach.htm#cross-sectional prevalence in each state">cross-sectional |
| prevalence</A> (observed for example at first interview) (<A | |
| <h5><font color="#EC5E5E" size="3"><b>- Variances of life | href="http://euroreves.ined.fr/imach/doc/imach.htm#Health expectancies">see |
| expectancies by age and initial health status</b></font><b>: </b><a | below</A>).</P> |
| href="vrbiaspar.txt"><b>vrbiaspar.txt</b></a></h5> | <H5><FONT color=#ec5e5e size=3><B>- Variances of life expectancies by age and |
| initial health status</B></FONT><B>: </B><A | |
| <p>For example, the covariances of life expectancies Cov(ei,ej) | href="http://euroreves.ined.fr/imach/doc/biaspar/vrbiaspar.txt"><B>biaspar/vrbiaspar.txt</B></A></H5> |
| at age 50 are (line 3) </p> | <P>For example, the covariances of life expectancies Cov(ei,ej) at age 50 are |
| (line 3) </P><PRE> Cov(e1,e1)=0.4776 Cov(e1,e2)=0.0488=Cov(e2,e1) Cov(e2,e2)=0.0424</PRE> | |
| <pre> Cov(e1,e1)=0.4776 Cov(e1,e2)=0.0488=Cov(e2,e1) Cov(e2,e2)=0.0424</pre> | <H5><FONT color=#ec5e5e size=3><B>-Variances of one-step probabilities |
| </B></FONT><B>: </B><A | |
| <h5><font color="#EC5E5E" size="3"><b>-Variances of one-step | href="http://euroreves.ined.fr/imach/doc/biaspar/probrbiaspar.txt"><B>biaspar/probrbiaspar.txt</B></A></H5> |
| probabilities </b></font><b>: </b><a href="probrbiaspar.txt"><b>probrbiaspar.txt</b></a></h5> | <P>For example, at age 65</P><PRE> p11=9.960e-001 standard deviation of p11=2.359e-004</PRE> |
| <H5><FONT color=#ec5e5e size=3><B>- </B></FONT><A | |
| <p>For example, at age 65</p> | name="Health expectancies"><FONT color=#ec5e5e size=3><B>Health |
| expectancies</B></FONT></A><FONT color=#ec5e5e size=3><B> with standard errors | |
| <pre> p11=9.960e-001 standard deviation of p11=2.359e-004</pre> | in parentheses</B></FONT><B>: </B><A |
| href="http://euroreves.ined.fr/imach/doc/biaspar/trbiaspar.txt"><FONT | |
| <h5><font color="#EC5E5E" size="3"><b>- </b></font><a | face="Courier New"><B>biaspar/trbiaspar.txt</B></FONT></A></H5><PRE>#Total LEs with variances: e.. (std) e.1 (std) e.2 (std) </PRE><PRE>70 13.26 (0.22) 9.95 (0.20) 3.30 (0.14) </PRE> |
| name="Health expectancies"><font color="#EC5E5E" size="3"><b>Health | <P>Thus, at age 70 the total life expectancy, e..=13.26 years is the weighted |
| expectancies</b></font></a><font color="#EC5E5E" size="3"><b> | mean of e1.=13.46 and e2.=11.35 by the period prevalences at age 70 which are |
| with standard errors in parentheses</b></font><b>: </b><a | 0.90134 in state 1 and 0.09866 in state 2 respectively (the sum is equal to |
| href="trbiaspar.txt"><font face="Courier New"><b>trbiaspar.txt</b></font></a></h5> | one). e.1=9.95 is the Disability-free life expectancy at age 70 (it is again a |
| weighted mean of e11 and e21). e.2=3.30 is also the life expectancy at age 70 to | |
| <pre>#Total LEs with variances: e.. (std) e.1 (std) e.2 (std) </pre> | be spent in the disability state.</P> |
| <H5><FONT color=#ec5e5e size=3><B>-Total life expectancy by age and health | |
| <pre>70 13.26 (0.22) 9.95 (0.20) 3.30 (0.14) </pre> | expectancies in states (1=healthy) and (2=disable)</B></FONT><B>: </B><A |
| href="Computing Health Expectancies using IMaCh_fichiers/ebiaspar1.png"><B>biaspar/ebiaspar1.png</B></A></H5> | |
| <p>Thus, at age 70 the total life expectancy, e..=13.26 years is | <P>This figure represents the health expectancies and the total life expectancy |
| the weighted mean of e1.=13.46 and e2.=11.35 by the stationary | with a confidence interval (dashed line). </P><PRE> <IMG height=300 src="Computing Health Expectancies using IMaCh_fichiers/ebiaspar1.png" width=400></PRE> |
| prevalence at age 70 which are 0.90134 in state 1 and 0.09866 in | <P>Standard deviations (obtained from the information matrix of the model) of |
| state 2, respectively (the sum is equal to one). e.1=9.95 is the | these quantities are very useful. Cross-longitudinal surveys are costly and do |
| Disability-free life expectancy at age 70 (it is again a weighted | not involve huge samples, generally a few thousands; therefore it is very |
| mean of e11 and e21). e.2=3.30 is also the life expectancy at age | important to have an idea of the standard deviation of our estimates. It has |
| 70 to be spent in the disability state.</p> | been a big challenge to compute the Health Expectancy standard deviations. Don't |
| be confused: life expectancy is, as any expected value, the mean of a | |
| <h5><font color="#EC5E5E" size="3"><b>-Total life expectancy by | distribution; but here we are not computing the standard deviation of the |
| age and health expectancies in states (1=healthy) and (2=disable)</b></font><b>: | distribution, but the standard deviation of the estimate of the mean.</P> |
| </b><a href="ebiaspar1.gif"><b>ebiaspar1.gif</b></a></h5> | <P>Our health expectancy estimates vary according to the sample size (and the |
| standard deviations give confidence intervals of the estimates) but also | |
| <p>This figure represents the health expectancies and the total | according to the model fitted. We explain this in more detail.</P> |
| life expectancy with the confident interval in dashed curve. </p> | <P>Choosing a model means at least two kind of choices. First we have to |
| decide the number of disability states. And second we have to design, within | |
| <pre> <img src="ebiaspar1.gif" width="400" height="300"></pre> | the logit model family, the model itself: variables, covariates, confounding |
| factors etc. to be included.</P> | |
| <p>Standard deviations (obtained from the information matrix of | <P>The more disability states we have, the better is our demographical |
| the model) of these quantities are very useful. | approximation of the disability process, but the smaller the number of |
| Cross-longitudinal surveys are costly and do not involve huge | transitions between each state and the higher the noise in the |
| samples, generally a few thousands; therefore it is very | measurement. We have not experimented enough with the various models |
| important to have an idea of the standard deviation of our | to summarize the advantages and disadvantages, but it is important to |
| estimates. It has been a big challenge to compute the Health | note that even if we had huge unbiased samples, the total life |
| Expectancy standard deviations. Don't be confuse: life expectancy | expectancy computed from a cross-longitudinal survey would vary with |
| is, as any expected value, the mean of a distribution; but here | the number of states. If we define only two states, alive or dead, we |
| we are not computing the standard deviation of the distribution, | find the usual life expectancy where it is assumed that at each age, |
| but the standard deviation of the estimate of the mean.</p> | people are at the same risk of dying. If we are differentiating the |
| alive state into healthy and disabled, and as mortality from the | |
| <p>Our health expectancies estimates vary according to the sample | disabled state is higher than mortality from the healthy state, we are |
| size (and the standard deviations give confidence intervals of | introducing heterogeneity in the risk of dying. The total mortality at |
| the estimate) but also according to the model fitted. Let us | each age is the weighted mean of the mortality from each state by the |
| explain it in more details.</p> | prevalence of each state. Therefore if the proportion of people at each age and |
| in each state is different from the period equilibrium, there is no reason to | |
| <p>Choosing a model means ar least two kind of choices. First we | find the same total mortality at a particular age. Life expectancy, even if it |
| have to decide the number of disability states. Second we have to | is a very useful tool, has a very strong hypothesis of homogeneity of the |
| design, within the logit model family, the model: variables, | population. Our main purpose is not to measure differential mortality but to |
| covariables, confonding factors etc. to be included.</p> | measure the expected time in a healthy or disabled state in order to maximise |
| the former and minimize the latter. But the differential in mortality | |
| <p>More disability states we have, better is our demographical | complicates the measurement.</P> |
| approach of the disability process, but smaller are the number of | <P>Incidences of disability or recovery are not affected by the number of states |
| transitions between each state and higher is the noise in the | if these states are independent. But incidence estimates are dependent on the |
| measurement. We do not have enough experiments of the various | specification of the model. The more covariates we add in the logit |
| models to summarize the advantages and disadvantages, but it is | model the better |
| important to say that even if we had huge and unbiased samples, | is the model, but some covariates are not well measured, some are confounding |
| the total life expectancy computed from a cross-longitudinal | factors like in any statistical model. The procedure to "fit the best model' is |
| survey, varies with the number of states. If we define only two | similar to logistic regression which itself is similar to regression analysis. |
| states, alive or dead, we find the usual life expectancy where it | We haven't yet been sofar because we also have a severe limitation which is the |
| is assumed that at each age, people are at the same risk to die. | speed of the convergence. On a Pentium III, 500 MHz, even the simplest model, |
| If we are differentiating the alive state into healthy and | estimated by month on 8,000 people may take 4 hours to converge. Also, the IMaCh |
| disable, and as the mortality from the disability state is higher | program is not a statistical package, and does not allow sophisticated design |
| than the mortality from the healthy state, we are introducing | variables. If you need sophisticated design variable you have to them your self |
| heterogeneity in the risk of dying. The total mortality at each | and and add them as ordinary variables. IMaCh allows up to 8 variables. The |
| age is the weighted mean of the mortality in each state by the | current version of this program allows only to add simple variables like age+sex |
| prevalence in each state. Therefore if the proportion of people | or age+sex+ age*sex but will never be general enough. But what is to remember, |
| at each age and in each state is different from the stationary | is that incidences or probability of change from one state to another is |
| equilibrium, there is no reason to find the same total mortality | affected by the variables specified into the model.</P> |
| at a particular age. Life expectancy, even if it is a very useful | <P>Also, the age range of the people interviewed is linked the age range of the |
| tool, has a very strong hypothesis of homogeneity of the | life expectancy which can be estimated by extrapolation. If your sample ranges |
| population. Our main purpose is not to measure differential | from age 70 to 95, you can clearly estimate a life expectancy at age 70 and |
| mortality but to measure the expected time in a healthy or | trust your confidence interval because it is mostly based on your sample size, |
| disability state in order to maximise the former and minimize the | but if you want to estimate the life expectancy at age 50, you should rely in |
| latter. But the differential in mortality complexifies the | the design of your model. Fitting a logistic model on a age range of 70 to 95 |
| measurement.</p> | and estimating probabilties of transition out of this age range, say at age 50, |
| is very dangerous. At least you should remember that the confidence interval | |
| <p>Incidences of disability or recovery are not affected by the | given by the standard deviation of the health expectancies, are under the strong |
| number of states if these states are independant. But incidences | assumption that your model is the 'true model', which is probably not the case |
| estimates are dependant on the specification of the model. More | outside the age range of your sample.</P> |
| covariates we added in the logit model better is the model, but | <H5><FONT color=#ec5e5e size=3><B>- Copy of the parameter file</B></FONT><B>: |
| some covariates are not well measured, some are confounding | </B><A |
| factors like in any statistical model. The procedure to "fit | href="http://euroreves.ined.fr/imach/doc/orbiaspar.txt"><B>orbiaspar.txt</B></A></H5> |
| the best model' is similar to logistic regression which itself is | <P>This copy of the parameter file can be useful to re-run the program while |
| similar to regression analysis. We haven't yet been sofar because | saving the old output files. </P> |
| we also have a severe limitation which is the speed of the | <H5><FONT color=#ec5e5e size=3><B>- Prevalence forecasting</B></FONT><B>: </B><A |
| convergence. On a Pentium III, 500 MHz, even the simplest model, | href="http://euroreves.ined.fr/imach/doc/biaspar/frbiaspar.txt"><B>biaspar/frbiaspar.txt</B></A></H5> |
| estimated by month on 8,000 people may take 4 hours to converge. | <P>First, we have estimated the observed prevalence between 1/1/1984 and |
| Also, the program is not yet a statistical package, which permits | 1/6/1988 (June, European syntax of dates). The mean date of all interviews |
| a simple writing of the variables and the model to take into | (weighted average of the interviews performed between 1/1/1984 and 1/6/1988) is |
| account in the maximisation. The actual program allows only to | estimated to be 13/9/1985, as written on the top on the file. Then we forecast |
| add simple variables like age+sex or age+sex+ age*sex but will | the probability to be in each state. </P> |
| never be general enough. But what is to remember, is that | <P>For example on 1/1/1989 : </P><PRE class=MsoNormal># StartingAge FinalAge P.1 P.2 P.3 |
| incidences or probability of change from one state to another is | |
| affected by the variables specified into the model.</p> | |
| <p>Also, the age range of the people interviewed has a link with | |
| the age range of the life expectancy which can be estimated by | |
| extrapolation. If your sample ranges from age 70 to 95, you can | |
| clearly estimate a life expectancy at age 70 and trust your | |
| confidence interval which is mostly based on your sample size, | |
| but if you want to estimate the life expectancy at age 50, you | |
| should rely in your model, but fitting a logistic model on a age | |
| range of 70-95 and estimating probabilties of transition out of | |
| this age range, say at age 50 is very dangerous. At least you | |
| should remember that the confidence interval given by the | |
| standard deviation of the health expectancies, are under the | |
| strong assumption that your model is the 'true model', which is | |
| probably not the case.</p> | |
| <h5><font color="#EC5E5E" size="3"><b>- Copy of the parameter | |
| file</b></font><b>: </b><a href="orbiaspar.txt"><b>orbiaspar.txt</b></a></h5> | |
| <p>This copy of the parameter file can be useful to re-run the | |
| program while saving the old output files. </p> | |
| <h5><font color="#EC5E5E" size="3"><b>- Prevalence forecasting</b></font><b>: | |
| </b><a href="frbiaspar.txt"><b>frbiaspar.txt</b></a></h5> | |
| <p | |
| style="TEXT-ALIGN: justify; tab-stops: 45.8pt 91.6pt 137.4pt 183.2pt 229.0pt 274.8pt 320.6pt 366.4pt 412.2pt 458.0pt 503.8pt 549.6pt 595.4pt 641.2pt 687.0pt 732.8pt">First, | |
| we have estimated the observed prevalence between 1/1/1984 and | |
| 1/6/1988. The mean date of interview (weighed average of the | |
| interviews performed between1/1/1984 and 1/6/1988) is estimated | |
| to be 13/9/1985, as written on the top on the file. Then we | |
| forecast the probability to be in each state. </p> | |
| <p | |
| style="TEXT-ALIGN: justify; tab-stops: 45.8pt 91.6pt 137.4pt 183.2pt 229.0pt 274.8pt 320.6pt 366.4pt 412.2pt 458.0pt 503.8pt 549.6pt 595.4pt 641.2pt 687.0pt 732.8pt">Example, | |
| at date 1/1/1989 : </p> | |
| <pre class="MsoNormal"># StartingAge FinalAge P.1 P.2 P.3 | |
| # Forecasting at date 1/1/1989 | # Forecasting at date 1/1/1989 |
| 73 0.807 0.078 0.115</pre> | 73 0.807 0.078 0.115</PRE> |
| <P>Since the minimum age is 70 on the 13/9/1985, the youngest forecasted age is | |
| <p | 73. This means that at age a person aged 70 at 13/9/1989 has a probability to |
| style="TEXT-ALIGN: justify; tab-stops: 45.8pt 91.6pt 137.4pt 183.2pt 229.0pt 274.8pt 320.6pt 366.4pt 412.2pt 458.0pt 503.8pt 549.6pt 595.4pt 641.2pt 687.0pt 732.8pt">Since | enter state1 of 0.807 at age 73 on 1/1/1989. Similarly, the probability to be in |
| the minimum age is 70 on the 13/9/1985, the youngest forecasted | state 2 is 0.078 and the probability to die is 0.115. Then, on the 1/1/1989, the |
| age is 73. This means that at age a person aged 70 at 13/9/1989 | prevalence of disability at age 73 is estimated to be 0.088.</P> |
| has a probability to enter state1 of 0.807 at age 73 on 1/1/1989. | <H5><FONT color=#ec5e5e size=3><B>- Population forecasting</B></FONT><B>: </B><A |
| Similarly, the probability to be in state 2 is 0.078 and the | href="http://euroreves.ined.fr/imach/doc/biaspar/poprbiaspar.txt"><B>biaspar/poprbiaspar.txt</B></A></H5><PRE># Age P.1 P.2 P.3 [Population] |
| probability to die is 0.115. Then, on the 1/1/1989, the | |
| prevalence of disability at age 73 is estimated to be 0.088.</p> | |
| <h5><font color="#EC5E5E" size="3"><b>- Population forecasting</b></font><b>: | |
| </b><a href="poprbiaspar.txt"><b>poprbiaspar.txt</b></a></h5> | |
| <pre># Age P.1 P.2 P.3 [Population] | |
| # Forecasting at date 1/1/1989 | # Forecasting at date 1/1/1989 |
| 75 572685.22 83798.08 | 75 572685.22 83798.08 |
| 74 621296.51 79767.99 | 74 621296.51 79767.99 |
| 73 645857.70 69320.60 </pre> | 73 645857.70 69320.60 </PRE><PRE># Forecasting at date 1/1/19909 |
| <pre># Forecasting at date 1/1/19909 | |
| 76 442986.68 92721.14 120775.48 | 76 442986.68 92721.14 120775.48 |
| 75 487781.02 91367.97 121915.51 | 75 487781.02 91367.97 121915.51 |
| 74 512892.07 85003.47 117282.76 </pre> | 74 512892.07 85003.47 117282.76 </PRE> |
| <P>From the population file, we estimate the number of people in each state. At | |
| <p>From the population file, we estimate the number of people in | age 73, 645857 persons are in state 1 and 69320 are in state 2. One year latter, |
| each state. At age 73, 645857 persons are in state 1 and 69320 | 512892 are still in state 1, 85003 are in state 2 and 117282 died before |
| are in state 2. One year latter, 512892 are still in state 1, | 1/1/1990.</P> |
| 85003 are in state 2 and 117282 died before 1/1/1990.</p> | <HR> |
| <hr> | <H2><A name=example></A><FONT color=#00006a>Trying an example</FONT></H2> |
| <P>Since you know how to run the program, it is time to test it on your own | |
| <h2><a name="example"></a><font color="#00006A">Trying an example</font></h2> | computer. Try for example on a parameter file named <A |
| href="http://euroreves.ined.fr/imach/doc/imachpar.imach">imachpar.imach</A> | |
| <p>Since you know how to run the program, it is time to test it | which is a copy of <FONT face="Courier New" size=2>mypar.imach</FONT> included |
| on your own computer. Try for example on a parameter file named <a | in the subdirectory of imach, <FONT face="Courier New" size=2>mytry</FONT>. Edit |
| href="..\mytry\imachpar.imach">imachpar.imach</a> which is a copy | it and change the name of the data file to <FONT face="Courier New" |
| of <font size="2" face="Courier New">mypar.imach</font> included | size=2>mydata.txt</FONT> if you don't want to copy it on the same directory. The |
| in the subdirectory of imach, <font size="2" face="Courier New">mytry</font>. | file <FONT face="Courier New">mydata.txt</FONT> is a smaller file of 3,000 |
| Edit it to change the name of the data file to <font size="2" | people but still with 4 waves. </P> |
| face="Courier New">..\data\mydata.txt</font> if you don't want to | <P>Right click on the .imach file and a window will popup with the string |
| copy it on the same directory. The file <font face="Courier New">mydata.txt</font> | '<STRONG>Enter the parameter file name:'</STRONG></P> |
| is a smaller file of 3,000 people but still with 4 waves. </p> | <TABLE border=1> |
| <TBODY> | |
| <p>Click on the imach.exe icon to open a window. Answer to the | <TR> |
| question:'<strong>Enter the parameter file name:'</strong></p> | <TD width="100%"><STRONG>IMACH, Version 0.97b</STRONG> |
| <P><STRONG>Enter the parameter file name: | |
| <table border="1"> | imachpar.imach</STRONG></P></TD></TR></TBODY></TABLE> |
| <tr> | <P>Most of the data files or image files generated, will use the 'imachpar' |
| <td width="100%"><strong>IMACH, Version 0.8a</strong><p><strong>Enter | string into their name. The running time is about 2-3 minutes on a Pentium III. |
| the parameter file name: ..\mytry\imachpar.imach</strong></p> | If the execution worked correctly, the outputs files are created in the current |
| </td> | directory, and should be the same as the mypar files initially included in the |
| </tr> | directory <FONT face="Courier New" size=2>mytry</FONT>.</P> |
| </table> | <UL> |
| <LI><PRE><U>Output on the screen</U> The output screen looks like <A href="http://euroreves.ined.fr/imach/doc/biaspar.log">biaspar.log</A> | |
| <p>Most of the data files or image files generated, will use the | |
| 'imachpar' string into their name. The running time is about 2-3 | |
| minutes on a Pentium III. If the execution worked correctly, the | |
| outputs files are created in the current directory, and should be | |
| the same as the mypar files initially included in the directory <font | |
| size="2" face="Courier New">mytry</font>.</p> | |
| <ul> | |
| <li><pre><u>Output on the screen</u> The output screen looks like <a | |
| href="imachrun.LOG">this Log file</a> | |
| # | # |
| title=MLE datafile=mydaiata.txt lastobs=3000 firstpass=1 lastpass=3 | |
| title=MLE datafile=..\data\mydata.txt lastobs=3000 firstpass=1 lastpass=3 | ftol=1.000000e-008 stepm=24 ncovcol=2 nlstate=2 ndeath=1 maxwav=4 mle=1 weight=0</PRE> |
| ftol=1.000000e-008 stepm=24 ncovcol=2 nlstate=2 ndeath=1 maxwav=4 mle=1 weight=0</pre> | <LI><PRE>Total number of individuals= 2965, Agemin = 70.00, Agemax= 100.92 |
| </li> | |
| <li><pre>Total number of individuals= 2965, Agemin = 70.00, Agemax= 100.92 | |
| Warning, no any valid information for:126 line=126 | Warning, no any valid information for:126 line=126 |
| Warning, no any valid information for:2307 line=2307 | Warning, no any valid information for:2307 line=2307 |
| Delay (in months) between two waves Min=21 Max=51 Mean=24.495826 | Delay (in months) between two waves Min=21 Max=51 Mean=24.495826 |
| <font face="Times New Roman">These lines give some warnings on the data file and also some raw statistics on frequencies of transitions.</font> | <FONT face="Times New Roman">These lines give some warnings on the data file and also some raw statistics on frequencies of transitions.</FONT> |
| Age 70 1.=230 loss[1]=3.5% 2.=16 loss[2]=12.5% 1.=222 prev[1]=94.1% 2.=14 | Age 70 1.=230 loss[1]=3.5% 2.=16 loss[2]=12.5% 1.=222 prev[1]=94.1% 2.=14 |
| prev[2]=5.9% 1-1=8 11=200 12=7 13=15 2-1=2 21=6 22=7 23=1 | prev[2]=5.9% 1-1=8 11=200 12=7 13=15 2-1=2 21=6 22=7 23=1 |
| Age 102 1.=0 loss[1]=NaNQ% 2.=0 loss[2]=NaNQ% 1.=0 prev[1]=NaNQ% 2.=0 </pre> | Age 102 1.=0 loss[1]=NaNQ% 2.=0 loss[2]=NaNQ% 1.=0 prev[1]=NaNQ% 2.=0 </PRE></LI></UL>It |
| </li> | includes some warnings or errors which are very important for you. Be careful |
| </ul> | with such warnings because your results may be biased if, for example, you have |
| people who accepted to be interviewed at first pass but never after. Or if you | |
| <p> </p> | don't have the exact month of death. In such cases IMaCh doesn't take any |
| initiative, it does only warn you. It is up to you to decide what to do with | |
| <ul> | these people. Excluding them is usually a wrong decision. It is better to decide |
| <li>Maximisation with the Powell algorithm. 8 directions are | that the month of death is at the mid-interval between the last two waves for |
| given corresponding to the 8 parameters. this can be | example. |
| rather long to get convergence.<br> | <P>If you survey suffers from severe attrition, you have to analyse the |
| <font size="1" face="Courier New"><br> | characteristics of the lost people and overweight people with same |
| Powell iter=1 -2*LL=11531.405658264877 1 0.000000000000 2 | characteristics for example. |
| 0.000000000000 3<br> | <P>By default, IMaCH warns and excludes these problematic people, but you have |
| 0.000000000000 4 0.000000000000 5 0.000000000000 6 | to be careful with such results. |
| 0.000000000000 7 <br> | <P> </P> |
| 0.000000000000 8 0.000000000000<br> | <UL> |
| 1..........2.................3..........4.................5.........<br> | <LI>Maximisation with the Powell algorithm. 8 directions are given |
| 6................7........8...............<br> | corresponding to the 8 parameters. this can be rather long to get |
| Powell iter=23 -2*LL=6744.954108371555 1 -12.967632334283 | convergence.<BR><FONT face="Courier New" size=1><BR>Powell iter=1 |
| <br> | -2*LL=11531.405658264877 1 0.000000000000 2 0.000000000000 3<BR>0.000000000000 |
| 2 0.135136681033 3 -7.402109728262 4 0.067844593326 <br> | 4 0.000000000000 5 0.000000000000 6 0.000000000000 7 <BR>0.000000000000 8 |
| 5 -0.673601538129 6 -0.006615504377 7 -5.051341616718 <br> | 0.000000000000<BR>1..........2.................3..........4.................5.........<BR>6................7........8...............<BR>Powell |
| 8 0.051272038506<br> | iter=23 -2*LL=6744.954108371555 1 -12.967632334283 <BR>2 0.135136681033 3 |
| 1..............2...........3..............4...........<br> | -7.402109728262 4 0.067844593326 <BR>5 -0.673601538129 6 -0.006615504377 7 |
| 5..........6................7...........8.........<br> | -5.051341616718 <BR>8 |
| #Number of iterations = 23, -2 Log likelihood = | 0.051272038506<BR>1..............2...........3..............4...........<BR>5..........6................7...........8.........<BR>#Number |
| 6744.954042573691<br> | of iterations = 23, -2 Log likelihood = 6744.954042573691<BR># |
| # Parameters<br> | Parameters<BR>12 -12.966061 0.135117 <BR>13 -7.401109 0.067831 <BR>21 |
| 12 -12.966061 0.135117 <br> | -0.672648 -0.006627 <BR>23 -5.051297 0.051271 </FONT><BR> |
| 13 -7.401109 0.067831 <br> | <LI><PRE><FONT size=2>Calculation of the hessian matrix. Wait... |
| 21 -0.672648 -0.006627 <br> | |
| 23 -5.051297 0.051271 </font><br> | |
| </li> | |
| <li><pre><font size="2">Calculation of the hessian matrix. Wait... | |
| 12345678.12.13.14.15.16.17.18.23.24.25.26.27.28.34.35.36.37.38.45.46.47.48.56.57.58.67.68.78 | 12345678.12.13.14.15.16.17.18.23.24.25.26.27.28.34.35.36.37.38.45.46.47.48.56.57.58.67.68.78 |
| Inverting the hessian to get the covariance matrix. Wait... | Inverting the hessian to get the covariance matrix. Wait... |
| Line 1232 Computing Variance-covariance of DFLEs: | Line 1036 Computing Variance-covariance of DFLEs: |
| Computing Total LEs with variances: file 'trmypar.txt' | Computing Total LEs with variances: file 'trmypar.txt' |
| Computing Variance-covariance of Prevalence limit: file 'vplrmypar.txt' | Computing Variance-covariance of Prevalence limit: file 'vplrmypar.txt' |
| End of Imach | End of Imach |
| </font></pre> | </FONT></PRE></LI></UL> |
| </li> | <P><FONT size=3>Once the running is finished, the program requires a |
| </ul> | character:</FONT></P> |
| <TABLE border=1> | |
| <p><font size="3">Once the running is finished, the program | <TBODY> |
| requires a caracter:</font></p> | <TR> |
| <TD width="100%"><STRONG>Type e to edit output files, g to graph again, c | |
| <table border="1"> | to start again, and q for exiting:</STRONG></TD></TR></TBODY></TABLE>In order to |
| <tr> | have an idea of the time needed to reach convergence, IMaCh gives an estimation |
| <td width="100%"><strong>Type e to edit output files, g | if the convergence needs 10, 20 or 30 iterations. It might be useful. |
| to graph again, c to start again, and q for exiting:</strong></td> | <P><FONT size=3>First you should enter <STRONG>e </STRONG>to edit the master |
| </tr> | file mypar.htm. </FONT></P> |
| </table> | <UL> |
| <LI><U>Outputs files</U> <BR><BR>- Copy of the parameter file: <A | |
| <p><font size="3">First you should enter <strong>e </strong>to | href="http://euroreves.ined.fr/imach/doc/ormypar.txt">ormypar.txt</A><BR>- |
| edit the master file mypar.htm. </font></p> | Gnuplot file name: <A |
| href="http://euroreves.ined.fr/imach/doc/mypar.gp.txt">mypar.gp.txt</A><BR>- | |
| <ul> | Cross-sectional prevalence in each state: <A |
| <li><u>Outputs files</u> <br> | href="http://euroreves.ined.fr/imach/doc/prmypar.txt">prmypar.txt</A> <BR>- |
| <br> | Period prevalence in each state: <A |
| - Copy of the parameter file: <a href="ormypar.txt">ormypar.txt</a><br> | href="http://euroreves.ined.fr/imach/doc/plrmypar.txt">plrmypar.txt</A> <BR>- |
| - Gnuplot file name: <a href="mypar.gp.txt">mypar.gp.txt</a><br> | Transition probabilities: <A |
| - Observed prevalence in each state: <a | href="http://euroreves.ined.fr/imach/doc/pijrmypar.txt">pijrmypar.txt</A><BR>- |
| href="prmypar.txt">prmypar.txt</a> <br> | Life expectancies by age and initial health status (estepm=24 months): <A |
| - Stationary prevalence in each state: <a | href="http://euroreves.ined.fr/imach/doc/ermypar.txt">ermypar.txt</A> <BR>- |
| href="plrmypar.txt">plrmypar.txt</a> <br> | Parameter file with estimated parameters and the covariance matrix: <A |
| - Transition probabilities: <a href="pijrmypar.txt">pijrmypar.txt</a><br> | href="http://euroreves.ined.fr/imach/doc/rmypar.txt">rmypar.txt</A> <BR>- |
| - Life expectancies by age and initial health status | Variance of one-step probabilities: <A |
| (estepm=24 months): <a href="ermypar.txt">ermypar.txt</a> | href="http://euroreves.ined.fr/imach/doc/probrmypar.txt">probrmypar.txt</A> |
| <br> | <BR>- Variances of life expectancies by age and initial health status |
| - Parameter file with estimated parameters and the | (estepm=24 months): <A |
| covariance matrix: <a href="rmypar.txt">rmypar.txt</a> <br> | href="http://euroreves.ined.fr/imach/doc/vrmypar.txt">vrmypar.txt</A><BR>- |
| - Variance of one-step probabilities: <a | Health expectancies with their variances: <A |
| href="probrmypar.txt">probrmypar.txt</a> <br> | href="http://euroreves.ined.fr/imach/doc/trmypar.txt">trmypar.txt</A> <BR>- |
| - Variances of life expectancies by age and initial | Standard deviation of period prevalences: <A |
| health status (estepm=24 months): <a href="vrmypar.txt">vrmypar.txt</a><br> | href="http://euroreves.ined.fr/imach/doc/vplrmypar.txt">vplrmypar.txt</A> |
| - Health expectancies with their variances: <a | <BR>No population forecast: popforecast = 0 (instead of 1) or stepm = 24 |
| href="trmypar.txt">trmypar.txt</a> <br> | (instead of 1) or model=. (instead of .)<BR><BR> |
| - Standard deviation of stationary prevalences: <a | <LI><U>Graphs</U> <BR><BR>-<A |
| href="vplrmypar.txt">vplrmypar.txt</a> <br> | href="http://euroreves.ined.fr/imach/mytry/pemypar1.gif">One-step transition |
| No population forecast: popforecast = 0 (instead of 1) or | probabilities</A><BR>-<A |
| stepm = 24 (instead of 1) or model=. (instead of .)<br> | href="http://euroreves.ined.fr/imach/mytry/pmypar11.gif">Convergence to the |
| <br> | period prevalence</A><BR>-<A |
| </li> | href="http://euroreves.ined.fr/imach/mytry/vmypar11.gif">Cross-sectional and |
| <li><u>Graphs</u> <br> | period prevalence in state (1) with the confident interval</A> <BR>-<A |
| <br> | href="http://euroreves.ined.fr/imach/mytry/vmypar21.gif">Cross-sectional and |
| -<a href="../mytry/pemypar1.gif">One-step transition | period prevalence in state (2) with the confident interval</A> <BR>-<A |
| probabilities</a><br> | href="http://euroreves.ined.fr/imach/mytry/expmypar11.gif">Health life |
| -<a href="../mytry/pmypar11.gif">Convergence to the | expectancies by age and initial health state (1)</A> <BR>-<A |
| stationary prevalence</a><br> | href="http://euroreves.ined.fr/imach/mytry/expmypar21.gif">Health life |
| -<a href="..\mytry\vmypar11.gif">Observed and stationary | expectancies by age and initial health state (2)</A> <BR>-<A |
| prevalence in state (1) with the confident interval</a> <br> | href="http://euroreves.ined.fr/imach/mytry/emypar1.gif">Total life expectancy |
| -<a href="..\mytry\vmypar21.gif">Observed and stationary | by age and health expectancies in states (1) and (2).</A> </LI></UL> |
| prevalence in state (2) with the confident interval</a> <br> | <P>This software have been partly granted by <A |
| -<a href="..\mytry\expmypar11.gif">Health life | href="http://euroreves.ined.fr/">Euro-REVES</A>, a concerted action from the |
| expectancies by age and initial health state (1)</a> <br> | European Union. It will be copyrighted identically to a GNU software product, |
| -<a href="..\mytry\expmypar21.gif">Health life | i.e. program and software can be distributed freely for non commercial use. |
| expectancies by age and initial health state (2)</a> <br> | Sources are not widely distributed today. You can get them by asking us with a |
| -<a href="..\mytry\emypar1.gif">Total life expectancy by | simple justification (name, email, institute) <A |
| age and health expectancies in states (1) and (2).</a> </li> | href="mailto:brouard@ined.fr">mailto:brouard@ined.fr</A> and <A |
| </ul> | href="mailto:lievre@ined.fr">mailto:lievre@ined.fr</A> .</P> |
| <P>Latest version (0.97b of June 2004) can be accessed at <A | |
| <p>This software have been partly granted by <a | href="http://euroreves.ined.fr/imach">http://euroreves.ined.fr/imach</A><BR></P></BODY></HTML> |
| href="http://euroreves.ined.fr">Euro-REVES</a>, a concerted | |
| action from the European Union. It will be copyrighted | |
| identically to a GNU software product, i.e. program and software | |
| can be distributed freely for non commercial use. Sources are not | |
| widely distributed today. You can get them by asking us with a | |
| simple justification (name, email, institute) <a | |
| href="mailto:brouard@ined.fr">mailto:brouard@ined.fr</a> and <a | |
| href="mailto:lievre@ined.fr">mailto:lievre@ined.fr</a> .</p> | |
| <p>Latest version (0.8a of May 2002) can be accessed at <a | |
| href="http://euroreves.ined.fr/imach">http://euroreves.ined.fr/imach</a><br> | |
| </p> | |
| </body> | |
| </html> |
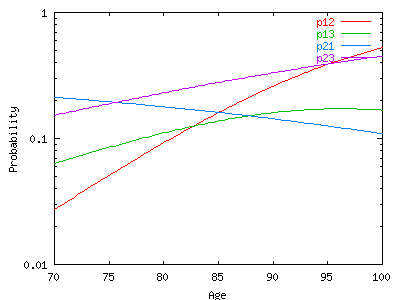{kind=link}
{kind=link}
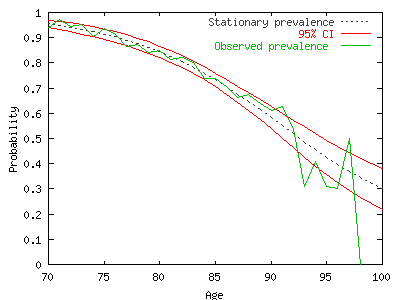{kind=link}
{kind=link}
{kind=link}
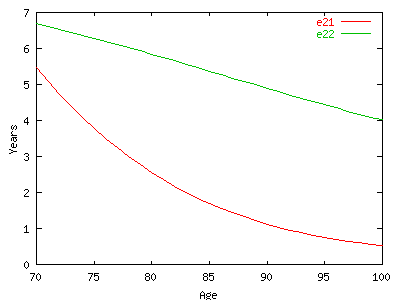{kind=link}
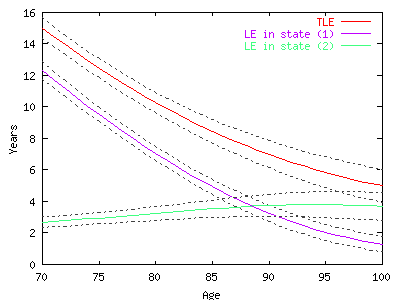{kind=link}